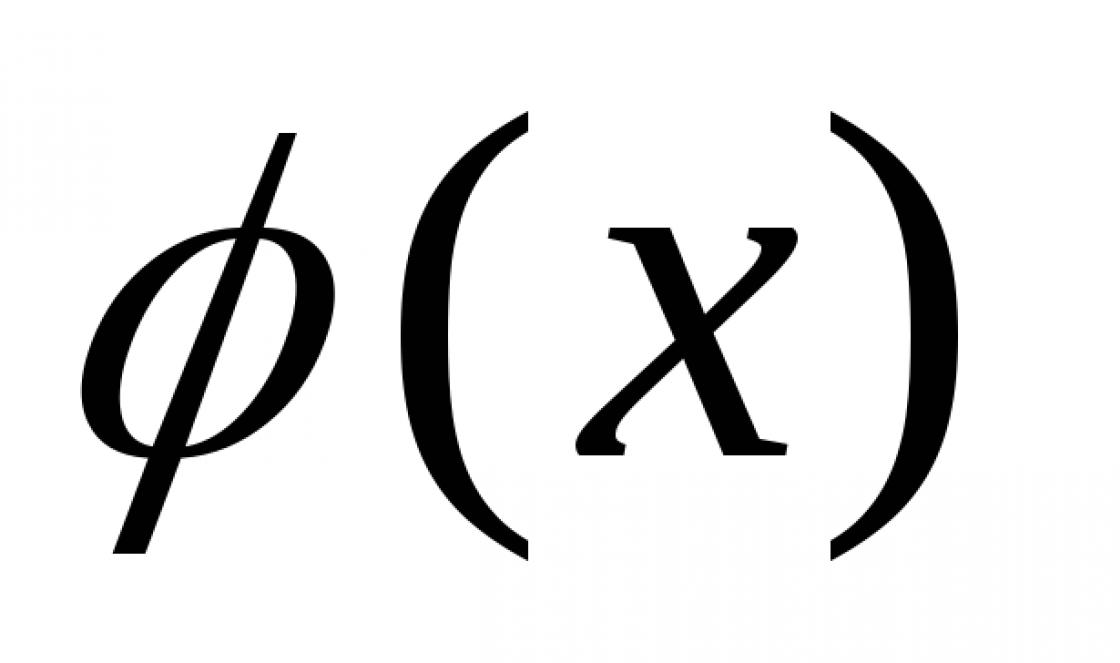Variační série. Polygon a histogram.
Rozsah distribuce- představuje uspořádané rozdělení studovaných jednotek populace do skupin podle určité proměnlivé charakteristiky.
V závislosti na charakteristice, která je základem tvorby distribuční řady, se rozlišují atributivní a variační distribuční řádky:
§ Volají se distribuční řady konstruované ve vzestupném nebo sestupném pořadí hodnot kvantitativní charakteristiky variační.
Variační řada distribuce se skládá ze dvou sloupců:
První sloupec poskytuje kvantitativní hodnoty proměnné charakteristiky, které se nazývají možnosti a jsou určeny. Diskrétní opce – vyjádřená jako celé číslo. Možnost intervalu se pohybuje od a do. V závislosti na typu voleb můžete vytvořit diskrétní nebo intervalovou řadu variací.
Druhý sloupec obsahuje počet konkrétní možnosti, vyjádřeno jako frekvence nebo frekvence:
Frekvence- jedná se o absolutní čísla, která ukazují, kolikrát se daná hodnota charakteristiky vyskytuje v souhrnu, což značí. Součet všech frekvencí se musí rovnat počtu jednotek v celé populaci.
Frekvence() jsou četnosti vyjádřené v procentech z celku. Součet všech frekvencí vyjádřený v procentech se musí rovnat 100 % ve zlomcích jedné.
Grafické znázornění distribuční řady
Distribuční série jsou vizuálně prezentovány pomocí grafických obrázků.
Distribuční série jsou znázorněny jako:
§ Mnohoúhelník
§ Histogramy
§ Kumuluje se
Polygon
Při konstrukci mnohoúhelníku se hodnoty proměnlivé charakteristiky vynesou na vodorovnou osu (osa x) a frekvence nebo frekvence se vynesou na svislou osu (osa y).
1. Mnohoúhelník na Obr. 6.1 vychází z údajů z mikrosčítání obyvatel Ruska v roce 1994.

sloupcový graf
Pro konstrukci histogramu jsou hodnoty hranic intervalů vyznačeny podél osy úsečky a na jejich základě jsou konstruovány obdélníky, jejichž výška je úměrná frekvencím (nebo frekvencím).
Na Obr. 6.2. ukazuje histogram rozložení ruské populace v roce 1997 podle věkových skupin.

Obr. 1. Rozložení ruské populace podle věkových skupin
Empirická distribuční funkce, vlastnosti.
Nechť je známo statistické rozdělení četností kvantitativní charakteristiky X. Označme počtem pozorování, ve kterých byla pozorována hodnota charakteristiky menší než x, a n celkový počet pozorování. Je zřejmé, že relativní četnost události X Empirická distribuční funkce (výběrová distribuční funkce) je funkce, která pro každou hodnotu x určuje relativní četnost události X Na rozdíl od empirické distribuční funkce vzorku se distribuční funkce populace nazývá teoretická distribuční funkce. Rozdíl mezi těmito funkcemi je v tom, že teoretická funkce určuje pravděpodobnost události X Jak n roste, relativní četnost události X Základní vlastnosti Nechť je stanoven základní výsledek. Potom je distribuční funkce diskrétního rozdělení dána následující pravděpodobnostní funkcí: kde a Matematické očekávání tohoto rozdělení je: Průměr vzorku je tedy teoretický průměr distribuce vzorků. Podobně je výběrový rozptyl teoretickým rozptylem výběrového rozdělení. Náhodná veličina má binomické rozdělení: Funkce distribuce vzorku je nestranný odhad distribuční funkce: Rozptyl funkce rozdělení vzorku má tvar: Podle silného zákona velkých čísel konverguje výběrová distribuční funkce téměř jistě k teoretické distribuční funkci: Výběrová distribuční funkce je asymptoticky normální odhad teoretické distribuční funkce. Pokud, pak Podle distribuce na . Stanovení empirické distribuční funkce Nechť $X$ je náhodná proměnná. $F(x)$ je distribuční funkce dané náhodné veličiny. Provedeme $n$ experimentů s danou náhodnou veličinou za stejných podmínek, nezávisle na sobě. V tomto případě získáme posloupnost hodnot $x_1,\ x_2\ $, ... ,$\ x_n$, která se nazývá vzorek. Definice 1 Každá hodnota $x_i$ ($i=1,2\ $, ... ,$ \ n$) se nazývá varianta. Jedním z odhadů teoretické distribuční funkce je empirická distribuční funkce. Definice 3 Empirická distribuční funkce $F_n(x)$ je funkce, která pro každou hodnotu $x$ určuje relativní četnost události $X \ kde $n_x$ je počet možností menší než $x$, $n$ je velikost vzorku. Rozdíl mezi empirickou funkcí a teoretickou je v tom, že teoretická funkce určuje pravděpodobnost jevu $X Podívejme se nyní na několik základních vlastností distribuční funkce. Rozsah funkce $F_n\left(x\right)$ je segment $$. $F_n\left(x\right)$ je neklesající funkce. $F_n\left(x\right)$ je levá spojitá funkce. $F_n\left(x\right)$ je po částech konstantní funkce a zvyšuje se pouze v bodech hodnot náhodné proměnné $X$ Nechť $X_1$ je nejmenší a $X_n$ největší varianta. Potom $F_n\left(x\right)=0$ pro $(x\le X)_1$ a $F_n\left(x\right)=1$ pro $x\ge X_n$. Zaveďme větu, která spojuje teoretické a empirické funkce. Věta 1 Nechť $F_n\left(x\right)$ je empirická distribuční funkce a $F\left(x\right)$ je teoretická distribuční funkce obecného vzorku. Pak platí rovnost: \[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\] Příklad 1 Nechte rozložení vzorkování zaznamenat následující data pomocí tabulky: Obrázek 1. Najděte velikost vzorku, vytvořte empirickou distribuční funkci a vykreslete ji. Velikost vzorku: $n=5+10+15+20=50$. Podle vlastnosti 5 máme to pro $x\le 1$ $F_n\left(x\right)=0$ a pro $x>4$ $F_n\left(x\right)=1$. Hodnota x $ Hodnota x $ Hodnota x $ Tak dostaneme: Obrázek 2 Obrázek 3 Příklad 2 Z měst střední části Ruska bylo náhodně vybráno 20 měst, pro která byly získány následující údaje o jízdném MHD: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13, 13, 12, 12, 15, 14, 14. Vytvořte pro tento vzorek empirickou distribuční funkci a vykreslete ji. Zapišme si vzorové hodnoty ve vzestupném pořadí a vypočítejme frekvenci každé hodnoty. Dostaneme následující tabulku: Obrázek 4. Velikost vzorku: $n=20$. Podle vlastnosti 5 máme to pro $x\le 12$ $F_n\left(x\right)=0$ a pro $x>15$ $F_n\left(x\right)=1$. Hodnota x $ Hodnota x $ Hodnota x $ Tak dostaneme: Obrázek 5. Nakreslete empirické rozdělení: Obrázek 6. Originalita: $92.12\%$. Přednáška 13. Pojem statistických odhadů náhodných veličin Nechť je známo statistické rozdělení četností kvantitativní charakteristiky X. Označme počtem pozorování, ve kterých byla pozorována hodnota charakteristiky menší než x, a n celkový počet pozorování. Je zřejmé, že relativní četnost události X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической. Empirická distribuční funkce(výběrová distribuční funkce) je funkce, která určuje pro každou hodnotu x relativní četnost události X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки. Na rozdíl od empirické distribuční funkce vzorku se nazývá distribuční funkce populace teoretické distribuční funkce. Rozdíl mezi těmito funkcemi je ten, že teoretická funkce určuje pravděpodobnost události X< x, тогда как эмпирическая – relativní četnost stejná událost. Jak n roste, relativní četnost události X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами Vlastnosti empirické distribuční funkce: 1) Hodnoty empirické funkce patří do segmentu 2) - neklesající funkce 3) Jestliže je nejmenší možnost, pak = 0 pro , jestliže je největší možnost, pak = 1 pro . Empirická distribuční funkce vzorku slouží k odhadu teoretické distribuční funkce populace. Příklad. Sestavme empirickou funkci založenou na rozdělení vzorku: Najdeme velikost vzorku: 12+18+30=60. Nejmenší možnost je 2, takže = 0 pro x £ 2. Hodnota x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Požadovaná empirická funkce má tedy tvar: Nejdůležitější vlastnosti statistických odhadů Budiž třeba studovat nějakou kvantitativní charakteristiku běžné populace. Předpokládejme, že z teoretických úvah to bylo možné zjistit který přesně rozdělení má znaménko a je potřeba odhadnout parametry, kterými se určuje. Pokud je například studovaná charakteristika v populaci normálně distribuována, je nutné odhadnout matematické očekávání a směrodatnou odchylku; pokud má charakteristika Poissonovo rozdělení, pak je nutné parametr l odhadnout. Obvykle jsou k dispozici pouze vzorová data, například hodnoty kvantitativní charakteristiky získané jako výsledek n nezávislých pozorování. Uvažujeme-li jako nezávislé náhodné proměnné, můžeme to říci najít statistický odhad neznámého parametru teoretického rozdělení znamená najít funkci pozorovaných náhodných veličin, která dává přibližnou hodnotu odhadovaného parametru.
Například pro odhad matematického očekávání normálního rozdělení hraje roli funkce aritmetický průměr Aby statistické odhady poskytovaly správné aproximace odhadovaných parametrů, musí splňovat určité požadavky, z nichž nejdůležitější jsou požadavky nepřemístěný
A platební schopnost
hodnocení. Nechť je statistický odhad neznámého parametru teoretického rozdělení. Nechť se odhad zjistí ze vzorku velikosti n. Pokus zopakujeme, tzn. vytěžme z obecné populace další stejně velký vzorek a na základě jeho dat získáme jiný odhad. Mnohonásobným opakováním experimentu dostaneme různá čísla. Skóre lze považovat za náhodnou veličinu a čísla za její možné hodnoty. Pokud odhad udává přibližnou hodnotu v hojnosti, tj. každé číslo je větší než skutečná hodnota a v důsledku toho je matematické očekávání (průměrná hodnota) náhodné proměnné větší než:. Stejně tak, pokud dá odhad s nevýhodou, Že . Použití statistického odhadu, jehož matematické očekávání se nerovná odhadovanému parametru, by tedy vedlo k systematickým chybám (stejného znaménka). Pokud naopak, pak je to zárukou proti systematickým chybám. Objektivní
nazývaný statistický odhad, jehož matematické očekávání se rovná odhadovanému parametru pro jakoukoli velikost vzorku. Přemístěno se nazývá odhad, který tuto podmínku nesplňuje. Nestrannost odhadu ještě nezaručuje dobrou aproximaci odhadovaného parametru, protože možné hodnoty mohou být velmi rozptýlené
kolem své průměrné hodnoty, tzn. rozptyl může být významný. V tomto případě se odhad zjištěný například z dat jednoho vzorku může ukázat jako výrazně vzdálený od průměrné hodnoty, a tedy i od odhadovaného parametru. Efektivní
je statistický odhad, který má pro danou velikost vzorku n nejmenší možný rozptyl
. Při zvažování velkých vzorků jsou nutné statistické odhady platební schopnost
. Bohatý
se nazývá statistický odhad, který, jak n®¥ směřuje v pravděpodobnosti k odhadovanému parametru. Například, pokud rozptyl nezkresleného odhadu má tendenci k nule jako n®¥, pak se takový odhad ukáže jako konzistentní. Průměr vzorku. Nechte extrahovat vzorek o velikosti n, abyste mohli studovat obecnou populaci ohledně kvantitativní charakteristiky X. Výběrový průměr je aritmetický průměr charakteristiky ve výběrové populaci.
Ukázkový rozptyl. Aby bylo možné pozorovat rozptyl kvantitativní charakteristiky hodnot vzorku kolem její průměrné hodnoty, je zavedena souhrnná charakteristika - rozptyl vzorku. Výběrový rozptyl je aritmetický průměr druhých mocnin odchylky pozorovaných hodnot charakteristiky od jejich střední hodnoty. Pokud jsou všechny hodnoty charakteristiky vzorku odlišné, pak Opravený rozptyl. Výběrový rozptyl je zkreslený odhad rozptylu populace, tzn. matematické očekávání výběrového rozptylu se nerovná odhadovanému obecnému rozptylu, ale je rovno Chcete-li opravit rozptyl vzorku, jednoduše jej vynásobte zlomkem Vzorový korelační koeficient se zjistí podle vzorce kde jsou vzorové směrodatné odchylky hodnot a . Vzorový korelační koeficient ukazuje blízkost lineárního vztahu mezi a : čím blíže k jednotě, tím silnější je lineární vztah mezi a . 23. Frekvenční mnohoúhelník je přerušovaná čára, jejíž segmenty spojují body. Pro konstrukci frekvenčního polygonu se varianty vynesou na osu úsečky a odpovídající frekvence na osu pořadnice a body se spojí úsečkami. Relativní frekvenční polygon je konstruován podobným způsobem s tím rozdílem, že relativní frekvence jsou vyneseny na ose pořadnice. Frekvenční histogram je stupňovitý útvar sestávající z obdélníků, jejichž základnami jsou dílčí intervaly délky h a výšky jsou rovny poměru. Pro sestavení frekvenčního histogramu se na osu vodorovné úsečky rozloží dílčí intervaly a nad nimi se nakreslí segmenty rovnoběžné s osou úsečky ve vzdálenosti (výšce). Plocha i-tého obdélníku se rovná součtu frekvencí intervalu i-o, proto je plocha frekvenčního histogramu rovna součtu všech frekvencí, tzn. velikost vzorku. Empirická distribuční funkce Kde n x- počet hodnot vzorku menší než X; n- velikost vzorku. 22 Definujme základní pojmy matematické statistiky .Základní pojmy matematické statistiky. Populace a vzorek. Variační řady, statistické řady. Seskupený vzorek. Seskupené statistické řady. Frekvenční mnohoúhelník. Funkce rozdělení vzorku a histogram.
Populace– celý soubor dostupných objektů. Vzorek– soubor objektů náhodně vybraných z běžné populace. Volá se sekvence voleb zapsaných ve vzestupném pořadí variační v blízkosti a seznam možností a jejich odpovídající frekvence nebo relativní frekvence - statistická řada: náhodně vybrané z běžné populace. Polygon frekvence se nazývá přerušovaná čára, jejíž segmenty spojují body. Histogram frekvence je stupňovitý obrazec skládající se z obdélníků, jejichž základnami jsou dílčí intervaly délky h a výšky se rovnají poměru . Vzorková (empirická) distribuční funkce zavolejte funkci F*(X), definující pro každou hodnotu X relativní četnost akce X< x.
Pokud se studuje nějaký spojitý rys, pak variační řada může sestávat z velmi velkého počtu čísel. V tomto případě je použití pohodlnější seskupený vzorek. Pro jeho získání je interval obsahující všechny pozorované hodnoty atributu rozdělen na několik stejných dílčích intervalů délky h a poté najděte pro každý dílčí interval n i– součet frekvencí varianty zahrnuté v i tý interval. 20. Zákon velkých čísel by neměl být chápán jako nějaký obecný zákon spojený s velkými čísly. Zákon velkých čísel je zobecněný název pro několik teorémů, z nichž vyplývá, že s neomezeným nárůstem počtu pokusů mají průměrné hodnoty tendenci k určitým konstantám. Patří mezi ně věty Chebyshev a Bernoulli. Čebyševova věta je nejobecnější zákon velkých čísel. Důkaz teorémů, spojený pojmem „zákon velkých čísel“, je založen na Čebyševově nerovnosti, která určuje pravděpodobnost odchylky od jejího matematického očekávání: 19Pearsonovo rozdělení (chi - čtverec) - rozdělení náhodné veličiny kde jsou náhodné proměnné X 1, X 2,…, X n nezávislé a mají stejnou distribuci N(0,1). V tomto případě počet termínů, tzn. n, se nazývá „počet stupňů volnosti“ rozdělení chí-kvadrát. Rozdělení chí-kvadrát se používá při odhadu rozptylu (pomocí intervalu spolehlivosti), při testování hypotéz shody, homogenity, nezávislosti, Rozdělení t Studentovo t je rozdělení náhodné veličiny kde jsou náhodné proměnné U A X nezávislý, U má standardní normální rozdělení N(0,1) a X– rozdělení chi – čtverec c n stupně svobody. V čem n se nazývá „počet stupňů volnosti“ Studentova rozdělení. Používá se při odhadu matematického očekávání, předpovědní hodnoty a dalších charakteristik pomocí intervalů spolehlivosti, testování hypotéz o hodnotách matematických očekávání, regresních koeficientů, Fisherovo rozdělení je rozdělení náhodné veličiny Fisherovo rozdělení se používá při testování hypotéz o adekvátnosti modelu v regresní analýze, rovnosti rozptylů a v dalších problémech aplikované statistiky. 18Lineární regrese je statistický nástroj používaný k předpovídání budoucích cen na základě minulých dat a obvykle se používá k určení, kdy jsou ceny přehřáté. Metoda nejmenších čtverců se používá k vytvoření „nejlépe padnoucí“ přímky přes řadu hodnotových bodů. Cenové body použité jako vstup mohou být některé z následujících: otevřené, zavřené, vysoké, nízké, 17. Dvourozměrná náhodná veličina je uspořádaná množina dvou náhodných veličin nebo . Příklad: Hodí se dvěma kostkami. – počet bodů hodených na první a druhé kostce Univerzálním způsobem, jak specifikovat distribuční zákon dvourozměrné náhodné veličiny, je distribuční funkce. 15.m.o Diskrétní náhodné proměnné Vlastnosti: 1) M(C) = C, C- konstantní; 2) M(CX) = CM.(X); 3) M(X 1 + X 2) = M(X 1) + M(X 2), kde X 1, X 2- nezávislé náhodné veličiny; 4) M(X 1 X 2) = M(X 1)M(X 2). Matematické očekávání součtu náhodných veličin se rovná součtu jejich matematických očekávání, tzn. Matematické očekávání rozdílu mezi náhodnými veličinami se rovná rozdílu jejich matematických očekávání, tzn. Matematické očekávání součinu náhodných veličin se rovná součinu jejich matematických očekávání, tzn. Pokud se všechny hodnoty náhodné proměnné zvýší (sníží) o stejné číslo C, pak se její matematické očekávání zvýší (sníží) o stejné číslo 14. Exponenciální(exponenciální)distribuční zákon X má zákon exponenciálního rozdělení s parametrem λ >0, pokud má hustota pravděpodobnosti tvar: Očekávaná hodnota: . Rozptyl: . Zákon exponenciálního rozdělení hraje velkou roli v teorii front a teorii spolehlivosti. 13. Zákon normálního rozdělení je charakterizován četností poruch a (t) nebo hustotou pravděpodobnosti poruchy f (t) ve tvaru: kde σ je směrodatná odchylka SV X; m X– matematické očekávání SV X. Tento parametr se často nazývá střed disperze nebo nejpravděpodobnější hodnota SV X. X– náhodná veličina, kterou lze brát jako čas, hodnotu proudu, hodnotu elektrického napětí a další argumenty. Normální zákon je dvouparametrový zákon, k jehož napsání potřebujete znát m X a σ. Normální rozdělení (Gaussovo rozdělení) se používá k posouzení spolehlivosti produktů, které jsou ovlivněny řadou náhodných faktorů, z nichž každý má nepatrný vliv na výsledný efekt 12. Zákon o jednotné distribuci. Spojitá náhodná veličina X má zákon o jednotné distribuci v segmentu [ A, b], je-li jeho hustota pravděpodobnosti na tomto segmentu konstantní a mimo něj rovna nule, tzn. Označení: . Očekávaná hodnota: . Rozptyl: . Náhodná hodnota X, distribuovaný podle jednotného zákona o segmentu se nazývá náhodné číslo od 0 do 1. Slouží jako výchozí materiál pro získání náhodných veličin s libovolným distribučním zákonem. Zákon o rovnoměrném rozdělení se používá při analýze chyb zaokrouhlování při provádění numerických výpočtů, v řadě problémů s řazením do fronty, při statistickém modelování pozorování podléhajících danému rozdělení. 11. Definice. Hustota distribuce pravděpodobností spojité náhodné veličiny X se nazývá funkce f(x)– první derivace distribuční funkce F(x). Také se nazývá hustota distribuce diferenciální funkce. Pro popis diskrétní náhodné veličiny je hustota distribuce nepřijatelná. Význam hustoty distribuce je ten, že ukazuje, jak často se náhodná veličina X objevuje v určitém okolí bodu X při opakování experimentů. Po představení distribučních funkcí a hustoty rozdělení lze uvést následující definici spojité náhodné veličiny. 10. Hustota pravděpodobnosti, hustota rozdělení pravděpodobnosti náhodné veličiny x, je funkce p(x) taková, že Je-li p(x) spojité, pak pro dostatečně malé ∆x pravděpodobnost nerovnosti x< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями Zjistěte, jaký je empirický vzorec. V chemii je EP nejjednodušší způsob, jak popsat sloučeninu - v podstatě seznam prvků, které tvoří sloučeninu na základě jejich procenta. Je třeba poznamenat, že tento jednoduchý vzorec nepopisuje objednat atomů ve sloučenině, jednoduše označuje, z jakých prvků se skládá. Například: Rozumějte pojmu „procentuální složení“."Procentuální složení" se týká procenta každého jednotlivého atomu v celé dotyčné sloučenině. Abyste našli empirický vzorec sloučeniny, musíte znát procentuální složení sloučeniny. Pokud hledáte empirický vzorec pro domácí úkol, pak budou s největší pravděpodobností uvedena procenta. Mějte na paměti, že se budete muset vypořádat s gramatomy. Gram atom je určité množství látky, jejíž hmotnost se rovná její atomové hmotnosti. Chcete-li najít atom gramu, musíte použít následující rovnici: Procento prvku ve sloučenině se vydělí atomovou hmotností prvku.
Vědět, jak najít atomové poměry. Při práci se sloučeninou skončíte s více než jedním gramatomem. Po nalezení všech gramatomů vaší sloučeniny se na ně podívejte. Abyste našli atomový poměr, budete muset vybrat nejmenší hodnotu gramatomů, kterou jste vypočítali. Pak budete muset rozdělit všechny gramatomy na nejmenší gramatomy. Například: Pochopte, jak převést hodnoty atomového poměru na celá čísla. Při psaní empirického vzorce musíte používat celá čísla. To znamená, že nemůžete použít čísla jako 1,33. Poté, co zjistíte poměr atomů, musíte převést zlomky (např. 1,33) na celá čísla (např. 3). Chcete-li to provést, musíte najít celé číslo vynásobením každého čísla atomového poměru, kterým získáte celá čísla. Například: - počet prvků vzorku rovný . Zejména pokud jsou všechny prvky vzorku odlišné, pak
- počet prvků vzorku rovný . Zejména pokud jsou všechny prvky vzorku odlišné, pak ![]() .
.![]() .
.![]() .
.![]() .
.![]() téměř jistě v .
téměř jistě v .Vlastnosti empirické distribuční funkce
Příklady úloh při hledání empirické distribuční funkce




Možnosti
Frekvence
![]()

![]()



![]()
![]()
 , (5.36)
, (5.36)

a pro jakékoli a< b вероятность события a < x < b равна
.
a pokud je F(x) diferencovatelný, pak ![]()