Consider some concepts and main approaches to classification errors. According to the method of calculation, errors can be divided into absolute and relative.
Absolute error is equal to the difference of the average measurement of the quantity X and the true value of this quantity:
In some cases, if necessary, calculate the errors of single determinations:

Note that the measured value in chemical analysis can be both the content of the component and the analytical signal. Depending on whether the result of the analysis overestimates or underestimates the error, the errors can be positive And negative.
Relative error can be expressed in fractions or percentages and usually has no sign:
 or
or 
It is possible to classify errors according to their sources of origin. Since there are extremely many sources of errors, their classification cannot be unambiguous.
Most often, errors are classified according to the nature of the causes that cause them. In this case, the errors are divided by systematicallysky and casual, misses (or gross errors) are also distinguished.
TO systematic include errors that are caused by a permanent cause, are constant in all measurements, or change according to a permanent law, can be identified and eliminated.
Random errors, the causes of which are unknown, can be estimated by methods of mathematical statistics.
miss - this is an error that sharply distorts the result of the analysis and is usually easily detected, caused, as a rule, by the negligence or incompetence of the analyst. On fig. 1.1 is a diagram explaining the concepts of systematic and errors and misses. Straight 1 corresponds to the ideal case when there are no systematic and random errors in all N definitions. Lines 2 and 3 are also idealized examples of chemical analysis. In one case (straight line 2), random errors are completely absent, but all N definitions have a constant negative systematic error Δх; otherwise (line 3) there is no systematic error. The line reflects the real situation 4: There are both random and systematic errors.

Rice. 4.2.1 Systematic and random errors of chemical analysis.
The division of errors into systematic and random is to a certain extent conditional.
The systematic errors of one sample of results, when considering a larger number of data, can turn into random ones. For example, a systematic error due to incorrect readings of the device, when measuring an analytical signal on different devices in different laboratories, becomes random.
Reproducibility characterizes the degree of closeness to each other of single definitions, the dispersion of single results relative to the average (Fig. 1.2).

Rice. 4.2..2. Reproducibility and accuracy of chemical analysis
In some cases along with the term "reproducibility" use the term "convergence". At the same time, convergence is understood as the dispersion of the results of parallel determinations, and reproducibility is the dispersion of the results obtained by different methods, in different laboratories, at different times, etc.
Right is the quality of the chemical analysis, reflecting the closeness of the systematic error to zero. Correctness characterizes the deviation of the obtained analysis result from the true value of the measured value (see Fig. 1.2).
Population - a hypothetical set of all conceivable results from -∞ to +∞;
An analysis of the experimental data shows that large errors are observed less often than small ones. It is also noted that with an increase in the number of observations, the same errors of different signs occur. equally often. These and other properties of random errors are described by a normal distribution or Gauss equation, which describes the probability density  .
.


Where X- the value of a random variable;
μ – general average (expected value- constant parameter);
Expected value-
for a continuous random variable is the limit to which the average tends  with an unlimited increase in the sample. Thus, the mathematical expectation is the average value for the entire population as a whole, sometimes it is called
general average.
with an unlimited increase in the sample. Thus, the mathematical expectation is the average value for the entire population as a whole, sometimes it is called
general average.
σ 2 -dispersion (constant parameter) - characterizes the dispersion of a random variable relative to its mathematical expectation;
σ is the standard deviation.
Dispersion- characterizes the dispersion of a random variable with respect to its mathematical expectation.
Sample population (sample)- the real number (n) of results that the researcher has, n = 3 ÷ 10.
Normal distribution law unacceptable to handle a small number of changes in the sample population (usually 3-10) - even if the population as a whole is normally distributed. For small samples, instead of a normal distribution, use Student's distribution (t– distribution), which links together the three main characteristics of the sample population -
The width of the confidence interval;
The corresponding probability;
Sample size.
Before processing data using methods of mathematical statistics, it is necessary to identify misses(gross errors) and exclude them from the results under consideration. One of the simplest is the method of detecting misses using Q - a criterion with the number of measurements n< 10:

Where R = X Max - X min– range of variation; X 1 - a suspiciously prominent value; x 2 - the result of a single determination, closest in value to X 1 .
The obtained value is compared with the critical value Q crit at a confidence level P = 0.95. If Q > Q crit, the drop result is a miss and is discarded.
Main characteristics of the sample. For sampling from n
results are calculated average, :
:

And dispersion, which characterizes the dispersion of results relative to the mean:

Dispersion in an explicit form cannot be used to quantify the dispersion of results, since its dimension does not match the dimension of the analysis result. To characterize scattering, use standard deviation,S.

This value is also called the standard (or standard) deviation or the standard error of a single result.
ABOUTrelative standard deviation or the coefficient of variation (V) is calculated from the relation

The variance of the arithmetic mean calculate:

and standard deviation of the mean

It should be noted that all values - dispersion, standard deviation and relative standard deviation, as well as the dispersion of the arithmetic mean and the standard deviation of the arithmetic mean - characterize the reproducibility of the results of chemical analysis.
Used in the processing of small (n<20) выборок из нормально распределенной генеральной совокупности t – распределение (т.е. распределение нормированной случайной величины) характеризуется соотношением

Wheret p , f – Student's distribution with the number of degrees of freedom f= n-1 and confidence level P=0.95(or significance level p=0.05).
The values of t - distributions are given in the tables, they are calculated for a sample in n results, the value of the confidence interval of the measured quantity for a given confidence probability according to the formula

Confidence interval characterizes both the reproducibility of the results of chemical analysis, and - if the true value of x ist is known - their correctness.
An example of performing control work No. 2
Exercise
At A air analysis for nitrogen content by chromatographic method for two series of experiments, the following results were obtained:
Solution:
We check the series for the presence of gross errors by the Q-criterion. Why we arrange the results in a descending order (from minimum to maximum or vice versa):
First episode:
77,90<77,92<77,95<77,99<78,05<78,07<78,08<78,10
We check the extreme results of the series (whether they contain a gross error).
The obtained value is compared with the tabular one (Table 2 of the application). For n=8, p=0.95 Q tab =0.55.
Because Q tab >Q 1 calculation, the leftmost digit is not a "miss".
Checking the rightmost digit

Qcalc The rightmost figure is also not erroneous. We have results of the second row yes in ascending order: 78,02<78,08<78,13<78,14<78,16<78,20<78,23<78,26. We check the extreme results of the experiments - whether they are erroneous. Q(n=8, p=0.95)=0.55. Table value. The leftmost value is not an error. The rightmost digit (is it wrong). Those. 0.125<0,55 The rightmost number is not a "miss". We subject the results of the experiments to statistical processing. We calculate the weighted average of the results: Dispersion relative to the mean: Standard deviation: Standard deviation of the arithmetic mean: For small (n<20)
выборках из нормально распределенной
генеральной совокупности следует
использовать t
– распределение, т.е. распределение
Стьюдента при числе степени свободы
f=n-1
и доверительной вероятности p=0,95. Using the tables of t - distribution, determine for a sample of n - results the value of the confidence interval of the measured value for a given confidence level. This interval can be calculated: WITH equalize the variances And average results two sample sets. Comparison of two variances is carried out using the F-distribution (Fisher distribution). If we have two sample populations with variances S 2 1 and S 2 2 and degrees of freedom f 1 =n 1 -1 and f 2 =n 2 -1, respectively, then we calculate the value of F: F=S 2 1 / S 2 2 And the numerator is always the larger of the two compared sample variances. The result obtained is compared with the table value. If F 0 > F crit (at p=0.95; n 1 , n 2), then the discrepancy between the variances is significant and the samples under consideration differ in reproducibility. If the difference between the variances is not significant, it is possible to compare the means x 1 and x 2 of the two sample sets, i.e. find out if there is a statistically significant difference between the test results. To solve the problem, use t - distribution. Pre-calculate the weighted average of two dispersions: And the weighted average standard deviation and then the value of t: Meaning t exp compare with t Crete with the number of degrees of freedom f=f 1 +f 2 =(n 1 +n 2 -2) and sample confidence level p=0.95. If at the same time t exp
>
t Crete, then the difference between the average Control task number 2 Air analysis for the content of component X by the chromatographic method for two series gave the following results (table-1). 3. Whether the results of both samples belong to the same general population. Test by Student's t test (p = 0.95; n = 8). Table-4.2.1- Initial data for control task No. 2 option number Component The methods of mathematical statistics are used, as a rule, at all stages of the analysis of research materials to choose a strategy for solving problems on specific sample data, evaluating the results obtained. Methods of mathematical statistics were used to process the material. Mathematical processing of materials makes it possible to clearly identify and evaluate the quantitative parameters of objective information, analyze and present them in various ratios and dependencies. They allow you to determine the measure of variation in the values in the collected materials containing quantitative information about a certain set of cases, some of which confirm the alleged connections, and some do not reveal them, calculate the reliability of quantitative differences between the selected sets of cases, and obtain other mathematical characteristics necessary for the correct interpretation of the facts. . The significance of the differences obtained during the study was determined by Student's t-test. The following values were calculated. 1. Arithmetic mean of the sample. Characterizes the average value of the population under consideration. Let us denote the measurement results. Then: where Y is the sum of all values when the current index i changes from 1 to n. 2. Standard deviation (standard deviation), which characterizes the dispersion, dispersion of the population under consideration relative to the arithmetic mean. = (x max - x min)/ k where is the standard deviation хmax - maximum value of the table; xmin - the minimum value of the table; k - coefficient 3. Standard error of the arithmetic mean or representativeness error (m). The standard error of the arithmetic mean characterizes the degree of deviation of the sample arithmetic mean from the arithmetic mean of the general population. The standard error of the arithmetic mean is calculated by the formula: where y is the standard deviation of the measurement results, n - sample size. The smaller m, the higher the stability, stability of the results. 4. Student's criterion. (in the numerator - the difference between the means of the two groups, in the denominator - the square root of the sum of the squares of the standard errors of these means). When processing the obtained results of the study, a computer program with the Excel package was used. The study was conducted by us according to generally accepted rules, and was carried out in 3 stages. At the first stage, the received material on the considered research problem was collected and analyzed. The subject of scientific research was formed. The analysis of the literature at this stage made it possible to specify the purpose and objectives of the study. The primary testing of the 30-meter running technique was carried out.<... class="gads_sm"> At the third stage, the material obtained as a result of scientific research was systematized, all available information on the research problem was summarized. The pilot study was conducted on the basis of the State Educational Institution "Lyakhovichi Secondary School", in total, the sample consisted of 20 students in grade 6 (11-12 years old). Chapter 3. Analysis of the results of the study As a result of the pedagogical experiment, we have identified the initial level of 30-meter running technique among students in the control and experimental groups (Appendices 1-2). Statistical processing of the obtained results allowed us to obtain the following data (table 6). Table 6. Initial level of running quality As can be seen from Table 6, the average number of points for athletes in the control and experimental groups does not statistically differ, in the experimental group the average score was 3.6 points, and in the control group 3.7 points. T-test in both groups temp=0.3; Р?0.05, at tcrit=2.1; The results of the initial testing showed that the indicators do not depend on training and are random. According to the initial testing, the running quality indicators of the control group slightly exceeded those of the experimental group. But there were no statistically significant differences in the groups, which is evidence of the identity of the students in the control and experimental groups in the technique of running 30m. During the experiment, in both groups, indicators characterizing the effectiveness of running technique improved. However, this improvement in different groups of participants in the experiment was of a different nature. As a result of training, a regular slight increase in indicators in the control group (3.8 points) was revealed. As can be seen from Appendix 2, a large increase in indicators was revealed in the experimental group. The students studied according to the program we proposed, which significantly improved their performance. Table 7. Changes in the quality of running in the subjects of the experimental group During the experiment, we found that increased loads in the experimental group gave significant improvements in the development of speed than in the control group. In adolescence, it is advisable to develop speed through the predominant use of physical education tools aimed at increasing the frequency of movements. At the age of 12-15 years, speed abilities increase, as a result of the use of mainly speed-strength and strength exercises that we used in the process of conducting physical education lessons and extracurricular activities in the sports section of basketball and athletics. When conducting classes in the experimental group, a strict phasing of complication and motor experience was carried out. Bugs were corrected in a timely manner. As the analysis of the actual data showed, the experimental teaching methodology had a significant change in the quality of the running technique (temp=2.4). The analysis of the results obtained in the experimental group and their comparison with the data obtained in the control group using the generally accepted teaching methods give grounds to assert that the method proposed by us will increase the effectiveness of teaching. Thus, at the stage of improving the methodology of 30m running at school, we revealed the dynamics of changes in testing indicators in the experimental and control groups. After the experiment, the quality of the reception performance increased in the experimental group to 4.9 points (t=3.3; P?0.05). By the end of the experiment, the quality of running technique in the experimental group was higher than in the control group. Math statistics is a branch of mathematics devoted to the methods of collecting, analyzing and processing the results of statistical observational data for scientific and practical purposes. Methods of mathematical statistics are used in those cases when they study the distribution mass phenomena, i.e. a large collection of objects or phenomena distributed on a certain basis. Let a set of homogeneous objects, united by a common feature or property of a qualitative or quantitative nature, be studied. Individual elements of such a set are called its members. The total number of members of a population is its volume. The set of all objects united by some attribute will be called general population. For example, the income of the population, the market value of shares or the deviation from the State Standard are studied in the course of a qualitative assessment of manufactured products. Mathematical statistics is closely related to the theory of probability and relies on its conclusions. In particular, the concept population in mathematical statistics corresponds to the concept space of elementary events in probability theory. The study of the entire general population is most often impossible or impractical due to significant material costs, damage or destruction of the object of study. Thus, it is impossible to obtain objective and complete information on the income of the population of the entire region; each individual inhabitant. Due to the deterioration of the research object, it is impossible to obtain reliable information about the quality, for example, of certain medicines or food products. Main task mathematical statistics is to study the general population based on sample data, depending on the goal, that is, the study of the probabilistic properties of the population: the law of distribution, numerical characteristics, etc. for making managerial decisions under conditions of uncertainty. One of the methods of mathematical statistics is sampling method. In practice, most often, not the entire population is studied, but a limited sample from it. sample(sample set) is a set of randomly selected objects. With the help of the sampling method, not the entire population is examined, but the sample ( X 1 ,X 2 ,...,x n) as a result of a limited number of observations. Then, according to the probabilistic properties of this sample, a judgment is made about the entire population from a certain general population. Various sampling methods are used to obtain a sample. The objects of study after the study can be in the general population, which corresponds to The sample is called representative or representative,
if it reproduces the general population well, that is, the probabilistic properties of the sample coincide or are close to the properties of the general population itself. So, the effectiveness of the application of the sampling method increases under a number of conditions, which include the following: Number of sample items studied enough to draw conclusions, that is, the sample is representative or " representative». So, a sufficient number of parts in a batch that is checked for quality (marriage) is established using the laws of probability theory and mathematical statistics. Sample items must be varied, taken randomly, those. principle must be respected randomization. Studied trait –
typical, is typical for all elements of the set of studied objects –
those. for the entire population. The trait being studied is significant for all elements of this class. A change in a sign of a statistical population studied by a sampling method is called variation, and the observed values of the feature x i
-
option. Absolute frequency
(frequency or frequency) options x i called the number of members of the population (general or sample) that have the value x i(i.e. this is the number of particles i-
th grade). Ranked grouping of the variant according to the individual values of the attribute (or according to the intervals of change), i.e. a sequence of options arranged in ascending order is called variational series. Any function ( X 1 ,X 2 ,…,X n) from the results of observations X 1 ,X 2 ,…,X n the random variable under study is called statistics. Accepted volume of the general population
designate N,
its absolute frequencies are N i, sample size - n,
its absolute frequencies are n i. It's obvious that The ratio of frequency to population size is called relative frequency or statistical probability and denoted W i
or If the number of options is large or close to the sample size (with a discrete distribution), and also if the sample is made from a continuous general population, then the variation series is not compiled by individual - point - values, but intervals population values. The variational series represented by the table, built using the grouping procedure, will be called interval. When compiling an interval variation series, the first line of the table is filled with intervals of values of the studied population equal in length, the second - with the corresponding absolute or relative frequencies. Let from some general population as a result n observations retrieved volume sample P.
Statistical distribution
samples called a list of options and their corresponding absolute or relative frequencies. Dot variation series absolute
frequencies can be represented by a table: x i X k n i n k and Dot variation series relative frequencies represented by a table: x i X k and When constructing an interval distribution, there are rules in choosing the number of intervals or the size of each interval. The criterion here is the optimal ratio: with an increase in the number of intervals, the representativeness improves, but the amount of data and the time for processing them increase. Difference x max
-
x min between the largest and smallest values is a variant called on a grand scale samples. To count the number of intervals k Sturgess' empirical formula is usually used: k= 1+3.3221g n (3.1) (assuming rounding to the nearest integer). Accordingly, the value of each interval h can be calculated using the formula: x min = x max -
0,5h. Each interval must contain at least five options. In the case when the number of options in the interval is less than five, it is customary to combine adjacent intervals. * This work is not a scientific work, is not a final qualifying work and is the result of processing, structuring and formatting the collected information, intended to be used as a source of material for self-preparation of educational work. Introduction. References. Methods of mathematical statistics Introduction. Basic concepts of mathematical statistics. Statistical processing of the results of psychological and pedagogical research. References. Methods of mathematical statistics Introduction. Basic concepts of mathematical statistics. Statistical processing of the results of psychological and pedagogical research. References. Introduction. The application of mathematics to other sciences makes sense only in conjunction with a deep theory of a particular phenomenon. It is important to keep this in mind so as not to stray into a simple game of formulas, which has no real content behind it. Academician Yu.A. Metropolitan Theoretical research methods in psychology and pedagogy make it possible to reveal the qualitative characteristics of the phenomena being studied. These characteristics will be fuller and deeper if the accumulated empirical material is subjected to quantitative processing. However, the problem of quantitative measurements in the framework of psychological and pedagogical research is very complex. This complexity lies primarily in the subjective-causal diversity of pedagogical activity and its results, in the very object of measurement, which is in a state of continuous movement and change. At the same time, the introduction of quantitative indicators into the study today is a necessary and obligatory component of obtaining objective data on the results of pedagogical work. As a rule, these data can be obtained both by direct or indirect measurement of various components of the pedagogical process, and by quantifying the relevant parameters of its adequately constructed mathematical model. To this end, in the study of problems of psychology and pedagogy, methods of mathematical statistics are used. With their help, various tasks are solved: processing of factual material, obtaining new, additional data, substantiation of the scientific organization of the study, and others. 2. Basic concepts of mathematical statistics An exceptionally important role in the analysis of many psychological and pedagogical phenomena is played by average values, which are a generalized characteristic of a qualitatively homogeneous population according to a certain quantitative attribute. It is impossible, for example, to calculate the average specialty or the average nationality of university students, since these are qualitatively heterogeneous phenomena. On the other hand, it is possible and necessary to determine, on average, a numerical characteristic of their performance (average score), the effectiveness of methodological systems and techniques, etc. In psychological and pedagogical research, various types of averages are usually used: arithmetic mean, geometric mean, median, mode, and others. The most common are the arithmetic mean, median and mode. The arithmetic mean is used in cases where there is a directly proportional relationship between the defining property and this feature (for example, when the performance of the study group improves, the performance of each of its members improves). The arithmetic mean is the quotient of dividing the sum of values by their number and is calculated by the formula: where X is the arithmetic mean; X1, X2, X3 ... Xn - the results of individual observations (techniques, actions), n - the number of observations (methods, actions), The sum of the results of all observations (techniques, actions). The median (Me) is a measure of the average position that characterizes the value of a feature on an ordered (built on the basis of increase or decrease) scale, which corresponds to the middle of the population under study. The median can be determined for ordinal and quantitative features. The location of this value is determined by the formula: Median location = (n + 1) / 2 For example. According to the results of the study, it was found that: – “excellent” students – 5 people from those participating in the experiment; – 18 people study “well”; - for "satisfactory" - 22 people; - for "unsatisfactory" - 6 people. Since in total N = 54 people took part in the experiment, the middle of the sample is equal to people. Hence, it is concluded that more than half of the students study below the “good” mark, that is, the median is more than “satisfactory”, but less than “good” (see figure). Mode (Mo) is the most common typical feature value among other values. It corresponds to the class with the highest frequency. This class is called modal value. For example. If the question of the questionnaire: “indicate the degree of knowledge of a foreign language”, the answers were distributed: 1 - fluent - 25 2 - I know enough to communicate - 54 3 - I know, but I have difficulties in communication - 253 4 - I understand with difficulty - 173 5 - do not know - 28 Obviously, the most typical meaning here is “I know, but I have difficulty communicating”, which will be modal. So the mode is -253. When using mathematical methods in psychological and pedagogical research, great importance is given to the calculation of variance and root-mean-square (standard) deviations. The variance is equal to the mean square of the deviations of the value of the options from the mean. It acts as one of the characteristics of individual results of the scatter of the values of the studied variable (for example, student grades) around the mean value. Calculation of the dispersion is carried out by determining: deviations from the average value; the square of the specified deviation; the sum of the squares of the deviation and the average value of the square of the deviation (see Table 6.1). The dispersion value is used in various statistical calculations, but is not directly observable. The quantity directly related to the content of the observed variable is the standard deviation. Table 6.1 Variance Calculation Example Meaning indicator Deviation from average deviations 2
– 3 = – 1 The standard deviation confirms the typicality and indicativeness of the arithmetic mean, reflects the measure of the fluctuation of the numerical values of the signs, from which the average value is derived. It is equal to the square root of the dispersion and is determined by the formula: where: - root mean square. With a small number of observations (actions) - less than 100 - in the value of the formula should be put not "N", but "N - 1". The arithmetic mean and mean square are the main characteristics of the results obtained during the study. They allow you to summarize the data, compare them, establish the advantages of one psychological and pedagogical system (program) over another. The root mean square (standard) deviation is widely used as a measure of dispersion for various characteristics. When evaluating the results of the study, it is important to determine the dispersion of a random variable around the mean value. This dispersion is described using the Gauss law (the law of the normal distribution of the probability of a random variable). The essence of the law is that when measuring a certain attribute in a given set of elements, there are always deviations in both directions from the norm due to many uncontrollable reasons, and the larger the deviations, the less often they occur. Further processing of the data can reveal: coefficient of variation (stability) the phenomenon under study, which is the percentage of the standard deviation to the arithmetic mean; measure of obliqueness, showing in which direction the predominant number of deviations is directed; measure of coolness, which shows the degree of accumulation of values of a random variable around the mean, etc. All these statistics help to more fully identify the signs of the phenomena being studied. Measures of association between variables. Relationships (dependencies) between two or more variables in statistics are called correlation. It is estimated using the value of the correlation coefficient, which is a measure of the degree and magnitude of this relationship. There are many correlation coefficients. Let us consider only a part of them, which take into account the presence of a linear relationship between the variables. Their choice depends on the scales for measuring the variables, the relationship between which must be assessed. The Pearson and Spearman coefficients are most often used in psychology and pedagogy. Consider the calculation of the values of the correlation coefficients on specific examples. Example 1. Let two compared variables X (marital status) and Y (exclusion from the university) be measured on a dichotomous scale (a special case of the title scale). To determine the relationship, we use the Pearson coefficient. In cases where there is no need to calculate the frequency of occurrence of different values of the variables X and Y, it is convenient to calculate the correlation coefficient using the contingency table (see Tables 6.2, 6.3, 6.4), showing the number of joint occurrences of pairs of values for two variables (features) . A - the number of cases when the variable X has a value equal to zero, and, at the same time, the variable Y has a value equal to one; B - the number of cases when the variables X and Y simultaneously have values equal to one; C is the number of cases when variables X and Y simultaneously have values equal to zero; D is the number of times when variable X has a value equal to one and, at the same time, variable Y has a value equal to zero. Table 6.2 General contingency table Feature X In general, the formula for the Pearson correlation coefficient for dichotomous data is Table 6.3 An example of data in a dichotomous scale Let us substitute data from the contingency table (see Table 6.4) corresponding to the example under consideration into the formula: Thus, the Pearson correlation coefficient for the selected example is 0.32, that is, the relationship between the marital status of students and the facts of exclusion from the university is insignificant. Example 2. If both variables are measured in order scales, then Spearman's rank correlation coefficient (Rs) is used as a measure of association. It is calculated according to the formula where Rs is Spearman's rank correlation coefficient; Di is the difference between the ranks of the compared objects; N is the number of compared objects. The value of the Spearman coefficient varies from -1 to + 1. In the first case, there is an unambiguous but oppositely directed relationship between the analyzed variables (with an increase in the values of one, the values of the other decrease). In the second, with the growth of the values of one variable, the value of the second variable proportionally increases. If the value of Rs is equal to zero or has a value close to it, then there is no significant relationship between the variables. As an example of calculating the Spearman coefficient, we use the data from Table 6.5. Table 6.5 Data and intermediate results of calculating the value of the coefficient rank correlation Rs Qualities Ranks assigned by an expert Rank Difference rank difference squared –1 Sum of squared rank differences Di = 22 Substitute the example data into the formula for the Smirman coefficient: The results of the calculation allow us to state that there is a fairly pronounced relationship between the variables under consideration. Statistical verification of a scientific hypothesis. The proof of the statistical reliability of the experimental influence differs significantly from the proof in mathematics and formal logic, where the conclusions are more universal in nature: statistical proofs are not so rigorous and final - they always allow the risk of making mistakes in the conclusions and therefore the validity of one or another is not finally proved by statistical methods. conclusion, but a measure of the likelihood of accepting a particular hypothesis is shown. A pedagogical hypothesis (a scientific assumption about the advantage of one or another method, etc.) is translated into the language of statistical science in the process of statistical analysis and re-formulated in at least two statistical hypotheses. The first (main) is called null hypothesis(H 0), in which the researcher talks about his starting position. He (a priori) seems to declare that the new method (suggested by him, his colleagues or opponents) does not have any advantages, and therefore from the very beginning the researcher is psychologically ready to take an honest scientific position: the differences between the new and old methods are declared equal to zero. In another alternative hypothesis(H 1) an assumption is made about the advantage of the new method. Sometimes several alternative hypotheses are put forward with appropriate notation. For example, the hypothesis about the advantage of the old method (H 2). Alternative hypotheses are accepted if and only if the null hypothesis is refuted. This happens in cases where the differences, say, in the arithmetic means of the experimental and control groups are so significant (statistically significant) that the risk of error in rejecting the null hypothesis and accepting the alternative does not exceed one of the three accepted significance levels statistical inference: - the first level - 5% (in scientific texts they sometimes write p \u003d 5% or a? 0.05, if presented in shares), where the risk of error in the conclusion is allowed in five cases out of a hundred theoretically possible similar experiments with a strictly random selection of subjects for each experiment; - the second level - 1%, i.e., accordingly, the risk of making a mistake is allowed only in one case out of a hundred (a? 0.01, with the same requirements); - the third level - 0.1%, i.e., the risk of making a mistake is allowed only in one case out of a thousand (a? 0.001). The last level of significance makes very high demands on the justification of the reliability of the experimental results and is therefore rarely used. When comparing the arithmetic means of the experimental and control groups, it is important not only to determine which average is greater, but also how much greater. The smaller the difference between them, the more acceptable will be the null hypothesis about the absence of statistically significant (significant) differences. Unlike thinking at the level of ordinary consciousness, which tends to perceive the difference in averages obtained as a result of experience as a fact and a basis for conclusion, a teacher-researcher who is familiar with the logic of statistical inference will not rush in such cases. He is likely to make an assumption that the differences are random, put forward a null hypothesis about the absence of significant differences in the results of the experimental and control groups, and only after the null hypothesis is refuted will he accept the alternative one. Thus, the question of differences within the framework of scientific thinking is transferred to another plane. The point is not only in differences (they almost always exist), but in the magnitude of these differences, and hence - in determining that difference and the boundary, after which one can say: yes, the differences are not random, they are statistically significant, which means that the subjects of these two groups belong after experiment is no longer to one (as before), but to two different general populations and that the level of preparedness of students potentially belonging to these populations will differ significantly. In order to show the boundaries of these differences, the so-called estimates of general parameters. Consider, using a specific example (see Table 6.6), how mathematical statistics can be used to disprove or confirm the null hypothesis. Suppose it is necessary to determine whether the effectiveness of students' group activity depends on the level of development of interpersonal relations in the study group. As a null hypothesis, an assumption is put forward that such a dependence does not exist, and as an alternative, a dependence exists. For these purposes, the results of the effectiveness of activities in two groups are compared, one of which in this case acts as an experimental group, and the second as a control group. To determine whether the difference between the average values of performance indicators in the first and second groups is significant (significant), it is necessary to calculate the statistical significance of this difference. To do this, you can use t - Student's criterion. It is calculated by the formula: where X 1 and X 2 - the arithmetic mean of the variables in groups 1 and 2; M 1 and M 2 are the values of the average errors, which are calculated by the formula: where is the root mean square, calculated by formula (2). Let's determine the errors for the first row (experimental group) and the second row (control group): We find the value of t - the criterion by the formula: Having calculated the value of the t-criterion, it is required, using a special table, to determine the level of statistical significance of differences between the average performance indicators in the experimental and control groups. The higher the value of the t-criterion, the higher the significance of the differences. To do this, we compare the calculated t with the tabular t. The tabular value is selected taking into account the selected confidence level (p = 0.05 or p = 0.01), and also depending on the number of degrees of freedom, which is found by the formula: where U is the number of degrees of freedom; N 1 and N 2 - the number of measurements in the first and second rows. In our example, U = 7 + 7 -2 = 12. Table 6.6 Data and intermediate results of calculating the significance of statistical Mean Differences Experimental group Control group The value of performance For table t - criterion, we find that the value of t table. = 3.055 for the one percent level (p However, the teacher-researcher should remember that the existence of a statistical significance of the difference in the average values is an important, but not the only argument in favor of the presence or absence of a relationship (dependence) between phenomena or variables. Therefore, it is necessary to involve other arguments for quantitative or substantive substantiation of a possible connection. Multidimensional methods of data analysis. Analysis of the relationship between a large number of variables is carried out by using multivariate methods of statistical processing. The purpose of applying such methods is to make visible hidden patterns, to highlight the most significant relationships between variables. Examples of such multivariate statistical methods are: - factor analysis; – cluster analysis; – analysis of variance; - regression analysis; – latent structural analysis; – multidimensional scaling and others. Factor analysis is to identify and interpret factors. A factor is a generalized variable that allows you to collapse some of the information, i.e. present it in a comprehensible form. For example, the factor theory of personality identifies a number of generalized characteristics of behavior, which in this case are called personality traits. cluster analysis allows you to highlight the leading feature and the hierarchy of feature relationships. Analysis of variance- a statistical method used to study one or more simultaneously acting and independent variables for the variability of an observed trait. Its peculiarity is that the observed feature can only be quantitative, while the explanatory features can be both quantitative and qualitative. Regression analysis allows you to identify a quantitative (numerical) dependence of the average value of changes in the resultant attribute (explained) on changes in one or more attributes (explanatory variables). As a rule, this type of analysis is used when it is required to find out how much the average value of one attribute changes when another attribute changes by one. Latent structural analysis represents a set of analytical and statistical procedures for identifying hidden variables (features), as well as the internal structure of the relationships between them. It makes it possible to explore the manifestations of complex interrelations of directly unobservable characteristics of socio-psychological and pedagogical phenomena. Latent analysis can be the basis for modeling these relationships. Multidimensional scaling provides a visual assessment of the similarity or difference between some objects described by a large number of various variables. These differences are represented as the distance between the estimated objects in a multidimensional space. 3. Statistical processing of the results of psychological and pedagogical research In any study, it is always important to ensure the mass character and representativeness (representativeness) of the objects of study. To resolve this issue, they usually resort to mathematical methods for calculating the minimum size of objects (groups of respondents) to be studied, so that objective conclusions can be drawn on this basis. According to the degree of completeness of coverage of primary units, statistics divides studies into continuous, when all units of the phenomenon under study are studied, and selective, if only a part of the population of interest, taken according to some attribute, is studied. The researcher does not always have the opportunity to study the entire set of phenomena, although this should be constantly strived for (there is not enough time, funds, necessary conditions, etc.); on the other hand, often a continuous study is simply not required, since the conclusions will be sufficiently accurate after studying a certain part of the primary units. The theoretical basis of the selective method of research is the theory of probability and the law of large numbers. In order for the study to have a sufficient number of facts, observations, a table of sufficiently large numbers is used. In this case, the researcher is required to establish the magnitude of the probability and the magnitude of the error allowed. Let, for example, the allowable error in the conclusions that should be made as a result of observations, in comparison with theoretical assumptions, should not exceed 0.05 both positively and negatively (in other words, we can make a mistake of no more than 5 cases out of 100). Then, according to the table of sufficiently large numbers (see Table 6.7), we find that the correct conclusion can be made in 9 cases out of 10 when the number of observations is at least 270, in 99 cases out of 100 if there are at least 663 observations, etc. e. Hence, as the accuracy and probability with which we are supposed to draw conclusions increases, the number of required observations increases. However, in a psychological and pedagogical study, it should not be excessively large. 300–500 observations is often quite sufficient for solid conclusions. This method of determining the sample size is the simplest. Mathematical statistics also has more complex methods for calculating the required sample sets, which are covered in detail in the specialized literature. However, compliance with the requirements of mass character does not yet ensure the reliability of the conclusions. They will be reliable when the units chosen for observation (conversations, experiments, etc.) are sufficiently representative for the class of phenomena being studied. Table 6.7 Brief table of sufficiently large numbers Value probabilities Permissible The representativeness of observation units is ensured primarily by their random selection using tables of random numbers. Suppose it is required to determine 20 training groups for conducting a mass experiment out of the available 200. To do this, a list of all groups is compiled, which is numbered. Then, 20 numbers are drawn from the table of random numbers, starting from any number, at a certain interval. These 20 random numbers, by observing the numbers, determine the groups that the researcher needs. A random selection of objects from the general (general) population gives grounds to assert that the results obtained in the study of a sample population of units will not differ sharply from those that would be available in the case of a study of the entire population of units. In the practice of psychological and pedagogical research, not only simple random selections are used, but also more complex selection methods: stratified random selection, multi-stage selection, etc. Mathematical and statistical methods of research are also means of obtaining new factual material. For this purpose, template techniques are used that increase the informative capacity of the questionnaire question and scaling, which makes it possible to more accurately assess the actions of both the researcher and the subjects. The scales arose because of the need to objectively and accurately diagnose and measure the intensity of certain psychological and pedagogical phenomena. Scaling makes it possible to streamline the phenomena, to quantify each of them, to determine the lowest and highest levels of the phenomenon under study. So, when studying the cognitive interests of listeners, one can set their boundaries: very great interest - very weak interest. Between these boundaries, introduce a number of steps that create a scale of cognitive interests: very great interest (1); great interest (2); medium (3); weak (4); very weak (5). In psychological and pedagogical research, different types of scales are used, for example, a) Three-dimensional scale Very active……..…………..10 Active……………………………5 Passive…...…………………...0 b) Multidimensional scale Very active…………………..8 Medium active………………….6 Not too active…………...4 Passive………………………..2 Completely passive…………...0 c) Bilateral scale. Very interested……………..10 Interested enough………...5 Indifferent……………………….0 Not interested…………………..5 Absolutely no interest………10 Numerical rating scales give each item a specific numerical designation. So, when analyzing the attitude of students to study, their perseverance in work, readiness for cooperation, etc. you can make a numerical scale based on the following indicators: 1 - unsatisfactory; 2 - weak; 3 - medium; 4 is above average, 5 is much above average. In this case, the scale takes the following form (see Table 6.8): Table 6.8 If the numerical scale is bipolar, the bipolar ordering is used with the zero value in the center: Discipline Indiscipline Pronounced 5 4 3 2 1 0 1 2 3 4 5 Not pronounced Rating scales can be displayed graphically. In this case, they express categories in a visual form. Moreover, each division (step) of the scale is characterized verbally. The considered methods play an important role in the analysis and generalization of the obtained data. They make it possible to establish various relationships, correlations between facts, to identify trends in the development of psychological and pedagogical phenomena. Thus, the grouping theory of mathematical statistics helps to determine which facts from the collected empirical material are comparable, on what basis they should be correctly grouped, and what degree of reliability they will be. All this makes it possible to avoid arbitrary manipulations with facts and to determine the program for their processing. Depending on the goals and objectives, three types of groupings are usually used: typological, variational and analytical. Typological grouping is used when it is necessary to break the received factual material into qualitatively homogeneous units (distribution of the number of discipline violations between different categories of students, breakdown of their performance indicators for physical exercises by years of study, etc.). If necessary, group the material according to the value of any changing (variable) attribute - a breakdown of groups of students by level of performance, by percentage of task completion, similar violations of the established order, etc. – applies variational grouping, which makes it possible to consistently judge the structure of the phenomenon under study. Analytical view of grouping helps to establish the relationship between the studied phenomena (the dependence of the degree of students' preparation on various teaching methods, the quality of tasks performed on temperament, abilities, etc.), their interdependence and interdependence in exact calculation. How important the work of the researcher in grouping the collected data is evidenced by the fact that errors in this work devalue the most comprehensive and meaningful information. At present, the mathematical foundations of grouping, typology, and classification have received the most profound development in sociology. Modern approaches and methods of typology and classification in sociological research can be successfully applied in psychology and pedagogy. In the course of the study, methods of final generalization of data are used. One of them is the technique of compiling and studying tables. When compiling a summary of data on one statistical value, a distribution series (variation series) of the value of this value is formed. An example of such a series (see Table 6.9) is a summary of data on the circumference of the chest of 500 faces. Table 6.9 A summary of data simultaneously for two or more statistical values involves the compilation of a distribution table that reveals the distribution of the values of one static value in accordance with the values that other values take. As an illustration, Table 6.10 is given, compiled on the basis of statistical data regarding the circumference of the chest and the weight of these people. Table 6.10 Chest circumference in cm The distribution table gives an idea of the relationship and connection that exists between the two values, namely: with a small weight, the frequencies are located in the upper left quarter of the table, which indicates the predominance of persons with a small chest circumference. As the weight increases towards the middle value, the frequency distribution moves to the center of the plate. This indicates that people who are closer to the average weight have a chest circumference that is also close to the average. With a further increase in the weight, the frequencies begin to occupy the lower right quarter of the plate. This indicates that in a person with a weight of more than average, the circumference of the chest is also above the average volume. It follows from the table that the established relationship is not strict (functional), but probabilistic, when with changes in the values of one quantity, the other changes as a trend, without a rigid unambiguous dependence. Such connections and dependencies are often found in psychology and pedagogy. Currently, they are usually expressed using correlation and regression analysis. Variational series and tables give an idea of the statics of the phenomenon, while the dynamics can be shown by series of development, where the first line contains successive stages or time intervals, and the second - the values of the studied statistical value obtained at these stages. Thus, an increase, decrease or periodic changes in the phenomenon under study are revealed, its tendencies and patterns are revealed. Tables can be filled with absolute values, or summary figures (average, relative). The results of statistical work - in addition to tables, they are often depicted graphically in the form of diagrams, figures, etc. The main ways of graphical representation of statistical values are: the method of points, the method of straight lines and the method of rectangles. They are simple and accessible to every researcher. The technique of their use is drawing coordinate axes, setting the scale, and issuing the designation of segments (points) on the horizontal and vertical axes. Diagrams depicting the distribution series of the values of one statistical quantity allow you to draw up distribution curves. A graphical representation of two (or more) statistical quantities makes it possible to form a certain curved surface, called the distribution surface. A number of developments in graphic execution form development curves. The graphic representation of statistical material allows one to penetrate deeper into the meaning of digital values, to catch their interdependence and features of the phenomenon under study, which are difficult to notice in the table. The researcher is freed from the work that he would have to do in order to deal with the abundance of numbers. Tables and graphs are important, but only the first steps in the study of statistical quantities. The main method is analytical, operating with mathematical formulas, with the help of which the so-called “generalizing indicators” are derived, that is, absolute values \u200b\u200bgiven in a comparable form (relative and average values, balances and indices). So, with the help of relative values (percentages), the qualitative features of the analyzed populations are determined (for example, the ratio of excellent students to the total number of students; the number of errors when working on complex equipment, caused by the mental instability of students, to the total number of errors, etc.). That is, the relationships are revealed: parts to the whole (specific gravity), terms to the sum (set structure), one part of the set to its other part; characterizing the dynamics of any changes over time, etc. As can be seen, even the most general idea of the methods of statistical calculation suggests that these methods have great potential in the analysis and processing of empirical material. Of course, the mathematical apparatus can dispassionately process everything that the researcher puts into it, both reliable data and subjective conjectures. That is why the perfect mastery of the mathematical apparatus for processing the accumulated empirical material in unity with a thorough knowledge of the qualitative characteristics of the phenomenon under study is necessary for every researcher. Only in this case is it possible to select high-quality, objective factual material, its qualified processing and obtaining reliable final data. This is a brief description of the most frequently used methods for studying the problems of psychology and pedagogy. It should be emphasized that none of the considered methods, taken by itself, can claim to be universal, to fully guarantee the objectivity of the data obtained. Thus, the elements of subjectivism in the answers obtained by interviewing respondents are obvious. The results of observations, as a rule, are not free from the subjective assessments of the researcher himself. Data taken from various documentation requires simultaneous verification of the authenticity of this documentation (especially personal documents, second-hand documents, etc.). Therefore, each researcher should strive, on the one hand, to improve the technique of applying any particular method, and on the other hand, to the complex, mutually controlling use of different methods to study the same problem. Possession of the entire system of methods makes it possible to develop a rational research methodology, clearly organize and conduct it, and obtain significant theoretical and practical results. References. Shevandrin N.I. Social psychology in education: Textbook. Part 1. Conceptual and applied foundations of social psychology. – M.: VLADOS, 1995. 2. Davydov V.P. Fundamentals of methodology, methodology and technology of pedagogical research: Scientific and methodological manual. - M .: Academy of the FSB, 1997. RANDOM VALUES AND THE LAWS OF THEIR DISTRIBUTION. Random called a quantity that takes values depending on the combination of random circumstances. Distinguish discrete
and random continuous
quantities. Discrete A quantity is called if it takes a countable set of values. ( Example: the number of patients at the doctor's office, the number of letters per page, the number of molecules in a given volume). Continuous called a quantity that can take values within a certain interval. ( Example: air temperature, body weight, human height, etc.) distribution law A random variable is a set of possible values of this quantity and, corresponding to these values, probabilities (or frequencies of occurrence). EXAMPLE: NUMERICAL CHARACTERISTICS OF RANDOM VALUES. In many cases, along with the distribution of a random variable or instead of it, information about these quantities can be provided by numerical parameters called numerical characteristics of a random variable
. The most commonly used of them: 1
.Expected value -
(average value) of a random variable is the sum of the products of all its possible values and the probabilities of these values: 2
.Dispersion
random variable: 3
.Standard deviation
: The THREE SIGMA rule - if a random variable is distributed according to the normal law, then the deviation of this value from the mean value in absolute value does not exceed three times the standard deviation ZON GAUSS - NORMAL DISTRIBUTION LAW Often there are values distributed over normal law
(Gauss' law). main feature
: it is the limiting law to which other laws of distribution approach. A random variable is normally distributed if its probability density
looks like: M(X)- mathematical expectation of a random variable; s- standard deviation. Probability Density(distribution function) shows how the probability related to the interval changes dx
random variable, depending on the value of the variable itself: BASIC CONCEPTS OF MATHEMATICAL STATISTICS Math statistics- a branch of applied mathematics, directly adjacent to the theory of probability. The main difference between mathematical statistics and probability theory is that mathematical statistics does not consider actions on distribution laws and numerical characteristics of random variables, but approximate methods for finding these laws and numerical characteristics based on experimental results. Basic concepts mathematical statistics are: 1.
General population;
2.
sample;
3.
variation series;
4.
fashion;
5.
median;
6.
percentile,
7.
frequency polygon,
8.
bar chart.
Population- a large statistical population from which some of the objects for research are selected (Example: the entire population of the region, university students of the city, etc.) Sample (sample population)- a set of objects selected from the general population. Variation series- statistical distribution, consisting of variants (values of a random variable) and their corresponding frequencies. Example: x- the value of a random variable (mass of girls aged 10 years); m- frequency of occurrence. Fashion– the value of the random variable, which corresponds to the highest frequency of occurrence. (In the example above, 24 kg is the most common value for fashion: m = 20). Median- the value of a random variable that divides the distribution in half: half of the values are located to the right of the median, half (no more) - to the left. Example: 1, 1, 1, 1, 1. 1, 2, 2, 2, 3
, 3, 4, 4, 5, 5, 5, 5, 6, 6, 7
, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8
, 8, 9, 9, 9, 10, 10, 10, 10, 10, 10 In the example, we observe 40 values of a random variable. All values are arranged in ascending order, taking into account the frequency of their occurrence. It can be seen that 20 (half) of the 40 values are located to the right of the selected value 7. So 7 is the median. To characterize the scatter, we find the values that were not higher than 25 and 75% of the measurement results. These values are called the 25th and 75th percentiles
. If the median bisects the distribution, then the 25th and 75th percentiles are cut off from it by a quarter. (The median itself, by the way, can be considered the 50th percentile.) As you can see from the example, the 25th and 75th percentiles are 3 and 8, respectively. use discrete
(point) statistical distribution and continuous
(interval) statistical distribution. For clarity, statistical distributions are depicted graphically in the form frequency polygon
or - histograms
. Frequency polygon- a broken line, the segments of which connect points with coordinates ( x 1 ,m 1), (x2,m2), ..., or for polygon of relative frequencies
- with coordinates ( x 1 ,p * 1), (x 2 ,p * 2), ...(Fig.1). Fig.1 Fig.2 Frequency histogram- a set of adjacent rectangles built on one straight line (Fig. 2), the bases of the rectangles are the same and equal dx
, and the heights are equal to the ratio of frequency to dx
, or R *
To dx
(probability density). Example: Frequency polygon The ratio of the relative frequency to the width of the interval is called probability density f(x)=m i / n dx = p* i / dx
An example of constructing a histogram . Let's use the data from the previous example. 1. Calculation of the number of class intervals Where n
- number of observations. In our case n = 100
. Hence: 2. Calculation of the interval width dx
: 3. Drawing up an interval series: bar chart


 - for the first row of results.
- for the first row of results. - for the second row of results.
- for the second row of results. - for the first row.
- for the first row. - for the second row.
- for the second row. - for the first row.
- for the first row. - for the second row.
- for the second row.





 And
And 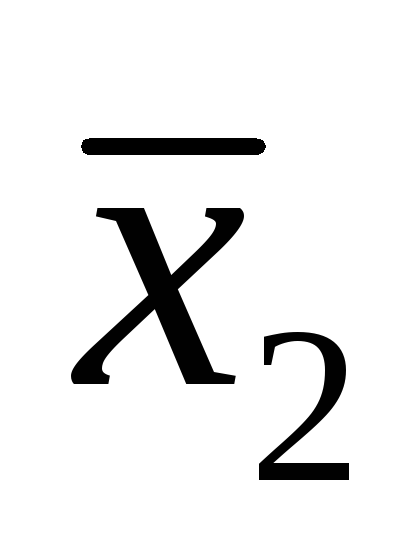 significant and the sample does not belong to the same general population. If t exp<
t крит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n 1 +n 2
результатов.
significant and the sample does not belong to the same general population. If t exp<
t крит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n 1 +n 2
результатов.
![]()
Organization of the study
3.1.1 Tasks and methods of mathematical statistics
3.1.2 Sample types
 sample.
sample. ,
,
 .
. :
: .
.
 .
.




 .
. . (3.2)
. (3.2)
–1
–1
x x 1 x2 x 3 x4 ...
x n
p p 1 p 2 p 3 p 4 ...
p n
x x 1 x2 x 3 x4 ...
x n
m m 1 m2 m 3 m4 ...
m n


X, kg
m

 m m i /n f(x)
m m i /n f(x)x, kg 2,7
2,8
2,9
3,0
3,1
3,2
3,3
3,4
3,5
3,6
3,7
3,8
3,9
4,0
4,1
4,2
4,3
4,4
m

![]()
 ,
, 
dx 2.7-2.9
2.9-3.1
3.1-3.3
3.3-3.5
3.5-3.7
3.7-3.9
3.9-4.1
4.1-4.3
4.3-4.5
m
f(x) 0.3
0.75
1.25
0.85
0.55
0.6
0.4
0.25
0.05