Mõelge mõnele mõisted ja peamised lähenemisviisid klassifikatsioon vead. Vastavalt arvutusmeetodile saab vead jagada absoluutseks ja suhteliseks.
Absoluutne viga on võrdne suuruse keskmise mõõtmise vahega X ja selle koguse tegelik väärtus:
Mõnel juhul arvutage vajaduse korral üksikute määramiste vead:

Pange tähele, et keemilises analüüsis võib mõõdetud väärtus olla nii komponendi sisu kui ka analüütiline signaal. Olenevalt sellest, kas analüüsi tulemus hindab viga üle või alahindab, võivad vead olla positiivne Ja negatiivne.
Suhteline viga võib väljendada murdarvudes või protsentides ja tavaliselt puudub märk:
 või
või 
Vigu on võimalik klassifitseerida nende tekkeallika järgi. Kuna vigade allikaid on äärmiselt palju, ei saa nende klassifikatsioon olla üheselt mõistetav.
Kõige sagedamini klassifitseeritakse vead neid põhjustavate põhjuste olemuse järgi. Sel juhul jagatakse vead arvuga süstemaatiliselttaevas ja juhuslik, eristatakse ka möödalaskmisi (või jämedaid vigu).
TO süstemaatiline sisaldavad vead, mis on põhjustatud püsivast põhjusest, on kõigil mõõtmistel konstantsed või muutuvad püsiva seaduse järgi, on tuvastatavad ja kõrvaldatavad.
Juhuslik vigu, mille põhjused pole teada, saab hinnata matemaatilise statistika meetoditega.
igatsema - see on analüüsi tulemust järsult moonutav ja tavaliselt kergesti tuvastatav viga, mille põhjuseks on reeglina analüütiku hooletus või ebakompetentsus. Joonisel fig. 1.1 on diagramm, mis selgitab süstemaatilise ning vigade ja möödalaskmiste mõisteid. Otse 1 vastab ideaaljuhule, kui kõigis N definitsioonides pole süstemaatilisi ja juhuslikke vigu. 2. ja 3. read on ka keemilise analüüsi idealiseeritud näited. Ühel juhul (sirge rida 2) juhuslikud vead täiesti puuduvad, kuid kõik N definitsioonidel on pidev negatiivne süstemaatiline viga Δх; muidu (rida 3) süstemaatilist viga pole. Rida peegeldab tegelikku olukorda 4: Esineb nii juhuslikke kui ka süstemaatilisi vigu.

Riis. 4.2.1 Keemilise analüüsi süstemaatilised ja juhuslikud vead.
Vigade jagamine süstemaatilisteks ja juhuslikeks on teatud määral tinglik.
Ühe tulemuste valimi süstemaatilised vead võivad suurema hulga andmeid arvesse võttes muutuda juhuslikeks. Näiteks seadme valedest näitudest tulenev süstemaatiline viga erinevates laborites erinevatel seadmetel analüütilise signaali mõõtmisel muutub juhuslikuks.
Reprodutseeritavus iseloomustab üksikute definitsioonide lähedusastet, üksikute tulemuste hajumist keskmise suhtes (joon. 1.2).

Riis. 4.2..2. Keemilise analüüsi reprodutseeritavus ja täpsus
Mõningatel juhtudel koos terminiga "reprodutseeritavus" kasutage seda terminit "konvergents". Samas mõistetakse konvergentsi all paralleelmääramiste tulemuste hajumist ning reprodutseeritavus on erinevatel meetoditel, erinevates laborites, erinevatel aegadel jne saadud tulemuste hajutamist.
Õige on keemilise analüüsi kvaliteet, mis peegeldab süstemaatilise vea lähedust nullile. Korrektsus iseloomustab saadud analüüsitulemuse hälvet mõõdetud väärtuse tegelikust väärtusest (vt joonis 1.2).
Rahvaarv - kõigi mõeldavate tulemuste hüpoteetiline kogum vahemikus -∞ kuni +∞;
Katseandmete analüüs näitab, et täheldatakse suuri vigu harvemini kui väikesed. Samuti märgitakse, et vaatluste arvu suurenemisega tekivad samad erinevate märkide vead. võrdselt sageli. Neid ja teisi juhuslike vigade omadusi kirjeldatakse normaaljaotusega või Gaussi võrrand, mis kirjeldab tõenäosustihedust  .
.


Kus X- juhusliku suuruse väärtus;
μ – üldine keskmine (oodatud väärtus- konstantne parameeter);
Oodatud väärtus-
pideva juhusliku muutuja jaoks on piir, milleni keskmine kaldub  valimi piiramatu suurenemisega. Seega on matemaatiline ootus kogu elanikkonna kui terviku keskmine väärtus, mõnikord nimetatakse seda
üldine keskmine.
valimi piiramatu suurenemisega. Seega on matemaatiline ootus kogu elanikkonna kui terviku keskmine väärtus, mõnikord nimetatakse seda
üldine keskmine.
σ 2 - dispersioon (konstantne parameeter) - iseloomustab juhusliku suuruse hajumist tema matemaatilise ootuse suhtes;
σ on standardhälve.
Dispersioon- iseloomustab juhusliku suuruse dispersiooni tema matemaatilise ootuse suhtes.
Näidispopulatsioon (näidis)- uurija tulemuste tegelik arv (n), n = 3 ÷ 10.
Normaaljaotuse seadus vastuvõetamatu et käsitleda väikest arvu muutusi valimipopulatsioonis (tavaliselt 3–10) – isegi kui üldkogum tervikuna on normaalselt jaotunud. Väikeste proovide puhul kasutage normaaljaotuse asemel Õpilaste jaotus (t- levitamine), mis seob kokku valimi üldkogumi kolm peamist tunnust –
Usaldusvahemiku laius;
Vastav tõenäosus;
Näidissuurus.
Enne andmete töötlemist matemaatilise statistika meetodite abil on vaja tuvastada igatseb(jämedad vead) ja jäta need vaadeldavatest tulemustest välja. Üks lihtsamaid on möödalaskmiste tuvastamise meetod Q abil - kriteerium mõõtmiste arvuga n< 10:

Kus R = X Max - X min– varieeruvus; X 1 - kahtlaselt silmapaistev väärtus; x 2 – ühekordse määramise tulemus, väärtuselt lähim X 1 .
Saadud väärtust võrreldakse kriitilise väärtusega Q crit usaldusnivooga P = 0,95. Kui Q > Q crit, on langemise tulemus möödalaskmine ja see jäetakse kõrvale.
Proovi peamised omadused. Proovide võtmiseks alates n
tulemused arvutatakse keskmine, :
:

Ja dispersioon, mis iseloomustab tulemuste hajumist keskmise suhtes:

Dispersiooni selgel kujul ei saa kasutada tulemuste hajumise kvantifitseerimiseks, kuna selle mõõde ei ühti analüüsitulemuse mõõtmega. Hajumise iseloomustamiseks kasutage standardhälve,S.

Seda väärtust nimetatakse ka standardhälbeks (või standardhälbeks) või üksiku tulemuse standardveaks.
KOHTAsuhteline standardhälve või variatsioonikordaja (V) arvutatakse seosest

Aritmeetilise keskmise dispersioon arvutama:

ja keskmise standardhälve

Tuleb märkida, et kõik väärtused - dispersioon, standardhälve ja suhteline standardhälve, samuti aritmeetilise keskmise dispersioon ja aritmeetilise keskmise standardhälve - iseloomustavad keemilise analüüsi tulemuste reprodutseeritavust.
Kasutatakse väikeste (n<20) выборок из нормально распределенной генеральной совокупности t – распределение (т.е. распределение нормированной случайной величины) характеризуется соотношением

Kust lk , f – Studenti jaotus vabadusastmete arvuga f= n-1 ja usalduse tase P = 0,95(või olulisuse tase p=0,05).
T - jaotuste väärtused on toodud tabelites, need on arvutatud valimi jaoks n tulemused, mõõdetud suuruse usaldusvahemiku väärtus antud usalduse tõenäosuse korral vastavalt valemile

Usaldusvahemik iseloomustab nii keemilise analüüsi tulemuste reprodutseeritavust kui ka - kui on teada x ist tegelik väärtus - nende õigsust.
Kontrolltöö nr 2 teostamise näide
Harjutus
Kell Aõhuanalüüs lämmastikusisalduse määramiseks kromatograafilise meetodiga kahe katseseeria jaoks, saadi järgmised tulemused:
Lahendus:
Kontrollime seeriat suurte vigade olemasolu suhtes Q-kriteeriumi järgi. Miks järjestame tulemused kahanevas järjekorras (minimaalsest maksimumini või vastupidi):
Esimene episood:
77,90<77,92<77,95<77,99<78,05<78,07<78,08<78,10
Kontrollime seeria äärmuslikke tulemusi (kas need sisaldavad jämedat viga).
Saadud väärtust võrreldakse tabeliga (taotluse tabel 2). Kui n = 8, p = 0,95 Q tab = 0,55.
Sest Q tab >Q 1 arvutus, vasakpoolseim number ei ole "miss".
Parempoolseima numbri kontrollimine

Qcalc Ka parempoolseim joonis ei ole ekslik. Meil on teise rea tulemused jah kasvavas järjekorras: 78,02<78,08<78,13<78,14<78,16<78,20<78,23<78,26. Kontrollime katsete äärmuslikke tulemusi – kas need on ekslikud. Q(n=8, p=0,95)=0,55. Tabeli väärtus. Vasakpoolseim väärtus ei ole viga. Kõige parempoolsem number (kas see on vale). Need. 0,125<0,55 Kõige parempoolsem number ei ole "miss". Allutame katsete tulemused statistilisele töötlemisele. Arvutame tulemuste kaalutud keskmise: Dispersioon keskmise suhtes: Standardhälve: Aritmeetilise keskmise standardhälve: Väikestele (n<20)
выборках из нормально распределенной
генеральной совокупности следует
использовать t
– распределение, т.е. распределение
Стьюдента при числе степени свободы
f=n-1
и доверительной вероятности p=0,95. Kasutades t - jaotuse tabeleid, määrake n - tulemuste valimi jaoks mõõdetud väärtuse usaldusvahemiku väärtus antud usaldusnivoo korral. Selle intervalli saab arvutada: KOOS võrdsustada dispersioone Ja keskmised tulemused kaks näidiskomplekti. Kahe dispersiooni võrdlemisel kasutatakse F-jaotust (Fisheri jaotus). Kui meil on kaks valimipopulatsiooni, mille dispersioon on S 2 1 ja S 2 2 ning vabadusastmed vastavalt f 1 =n 1 -1 ja f 2 =n 2 -1, siis arvutame F väärtuse: F=S 2 1 / S 2 2 Ja lugeja on alati neist kahest suurem võrdles valimi dispersioone. Saadud tulemust võrreldakse tabeli väärtusega. Kui F 0 > F crit (p=0,95 juures; n 1, n 2), siis on dispersioonide lahknevus oluline ja vaadeldavad valimid erinevad reprodutseeritavuse poolest. Kui lahknevus dispersioonide vahel ei ole oluline, on võimalik võrrelda kahe valimihulga keskmisi x 1 ja x 2, s.o. uuri, kas testitulemuste vahel on statistiliselt oluline erinevus. Ülesande lahendamiseks kasutage t - jaotust. Eelarvestage kahe dispersiooni kaalutud keskmine: Ja kaalutud keskmine standardhälve ja siis t väärtus: Tähendus t eksp Võrdle t Kreeta vabadusastmete arvuga f=f 1 +f 2 =(n 1 +n 2 -2) ja valimi usaldusnivooga p=0,95. Kui samal ajal t eksp
>
t Kreeta, siis keskmise vahe Kontrollülesanne number 2 Kahe seeria kromatograafilise meetodiga komponendi X sisalduse õhuanalüüs andis järgmised tulemused (tabel-1). 3. Kas mõlema valimi tulemused kuuluvad samasse üldkogumisse. Test Studenti t-testiga (p = 0,95; n = 8). Tabel-4.2.1- Kontrollülesande nr 2 lähteandmed valiku number Komponent Matemaatilise statistika meetodeid kasutatakse reeglina uurimismaterjalide analüüsi kõikides etappides, et valida konkreetsete näidisandmete põhjal ülesannete lahendamise strateegia, hinnates saadud tulemusi. Materjali töötlemiseks kasutati matemaatilise statistika meetodeid. Materjalide matemaatiline töötlemine võimaldab selgelt tuvastada ja hinnata objektiivse teabe kvantitatiivseid parameetreid, analüüsida ja esitada neid erinevates suhetes ja sõltuvustes. Need võimaldavad teil määrata kogutud materjalide väärtuste varieerumise mõõte, mis sisaldab kvantitatiivset teavet teatud juhtumite kogumi kohta, millest mõned kinnitavad väidetavaid seoseid ja mõned ei paljasta neid, arvutada kvantitatiivsete erinevuste usaldusväärsuse. valitud juhtumite kogumid, saada muid matemaatilisi tunnuseid, mis on vajalikud faktide õigeks tõlgendamiseks. Uuringu käigus saadud erinevuste olulisus määrati Studenti t-testiga. Arvutati järgmised väärtused. 1. Valimi aritmeetiline keskmine. Iseloomustab vaadeldava populatsiooni keskmist väärtust. Märgistame mõõtmistulemused. Seejärel: kus Y on kõigi väärtuste summa, kui praegune indeks i muutub 1-lt n-ks. 2. Standardhälve (standardhälve), mis iseloomustab vaadeldava üldkogumi hajumist, hajumist aritmeetilise keskmise suhtes. = (x max - x min)/ k kus on standardhälve хmax - tabeli maksimaalne väärtus; xmin - tabeli minimaalne väärtus; k - koefitsient 3. Aritmeetilise keskmise standardviga või representatiivsusviga (m). Aritmeetilise keskmise standardviga iseloomustab valimi aritmeetilise keskmise hälbe astet üldkogumi aritmeetilisest keskmisest. Aritmeetilise keskmise standardviga arvutatakse järgmise valemi abil: kus y on mõõtmistulemuste standardhälve, n - valimi suurus. Mida väiksem m, seda suurem on tulemuste stabiilsus, stabiilsus. 4. Õpilase kriteerium. (lugejas - kahe rühma keskmiste erinevus, nimetajas - nende keskmiste standardvigade ruutude summa ruutjuur). Saadud uuringutulemuste töötlemisel kasutati Exceli paketiga arvutiprogrammi. Uuringu viisime läbi üldtunnustatud reeglite järgi ja see viidi läbi 3 etapis. Esimeses etapis koguti ja analüüsiti vaadeldava uurimisprobleemi kohta saadud materjal. Moodustati teadusliku uurimistöö teema. Kirjanduse analüüs selles etapis võimaldas täpsustada uuringu eesmärki ja eesmärke. Viidi läbi 30 meetri jooksutehnika esmane katsetamine.<... class="gads_sm"> Kolmandas etapis süstematiseeriti teadusliku uurimistöö tulemusena saadud materjal, võeti kokku kogu olemasolev informatsioon uurimisprobleemi kohta. Pilootuuring viidi läbi riikliku õppeasutuse „Ljahovitši Keskkool“ baasil, kokku kuulus valimisse 20 6. klassi õpilast (11-12-aastased). Peatükk 3. Uuringu tulemuste analüüs Pedagoogilise eksperimendi tulemusena oleme kontroll- ja katserühma õpilaste seas tuvastanud 30 meetri jooksutehnika algtaseme (lisad 1-2). Saadud tulemuste statistiline töötlemine võimaldas saada järgmised andmed (tabel 6). Tabel 6. Jooksukvaliteedi esialgne tase Nagu nähtub tabelist 6, siis kontroll- ja katserühma sportlaste keskmine punktide arv statistiliselt ei erine, katserühmas oli keskmine punktisumma 3,6 punkti, kontrollrühmas aga 3,7 punkti. T-test mõlemas rühmas temp=0,3; Р?0,05, tcrit = 2,1 juures; Esmase testimise tulemused näitasid, et näitajad ei sõltu treeningust ja on juhuslikud. Esmase testimise järgi ületasid kontrollrühma jooksukvaliteedi näitajad veidi katserühma omasid. Kuid rühmades statistiliselt olulisi erinevusi ei olnud, mis annab tunnistust kontroll- ja katserühma õpilaste identiteedist 30 m jooksu tehnikas. Katse käigus paranesid mõlemas rühmas jooksutehnika efektiivsust iseloomustavad näitajad. See paranemine erinevates katses osalejate rühmades oli aga erineva iseloomuga. Treeningu tulemusena ilmnes kontrollgrupi näitajate regulaarne kerge tõus (3,8 punkti). Nagu näha lisast 2, ilmnes katserühmas suur näitajate tõus. Õpilased õppisid meie pakutud programmi järgi, mis parandas oluliselt nende sooritust. Tabel 7. Muutused jooksmise kvaliteedis katserühma katsealustel Katse käigus avastasime, et suurenenud koormused katserühmas andsid kiiruse arengus olulise paranemise kui kontrollrühmas. Noorukieas on soovitav kiirust arendada, kasutades valdavalt kehalise kasvatuse vahendeid, mille eesmärk on liigutuste sageduse suurendamine. 12-15-aastaselt tõusevad kiirusvõimed, mis tuleneb peamiselt kiirus-jõu- ja jõuharjutuste kasutamisest, mida kasutasime kehalise kasvatuse tundide läbiviimisel ja kooliväliste tegevuste läbiviimisel korvpalli ja kergejõustiku spordiosas. Katserühmas tundide läbiviimisel viidi läbi komplikatsioonide ja motoorsete kogemuste range järkjärgulisus. Vead parandati õigeaegselt. Nagu tegelike andmete analüüs näitas, oli eksperimentaalse õpetamise metoodikaga oluline muutus jooksutehnika kvaliteedis (temp=2,4). Katserühmas saadud tulemuste analüüs ja nende võrdlemine kontrollrühmas saadud andmetega üldtunnustatud õppemeetodite abil annab alust väita, et meie poolt välja pakutud meetod tõstab õppetöö efektiivsust. Nii selguski koolis 30m jooksu metoodika täiustamise etapis katse- ja kontrollgrupi testimisnäitajate muutuste dünaamika. Pärast katset tõusis vastuvõtu tulemuslikkuse kvaliteet katserühmas 4,9 punktini (t=3,3; P?0,05). Katse lõpuks oli katserühma jooksutehnika kvaliteet kõrgem kui kontrollrühmas. Matemaatika statistika on matemaatika haru, mis on pühendatud statistiliste vaatlusandmete kogumise, analüüsimise ja töötlemise meetoditele teaduslikel ja praktilistel eesmärkidel. Matemaatilise statistika meetodeid kasutatakse nendel juhtudel, kui nad uurivad jaotust massinähtused, st. laiali jagatud suur objektide või nähtuste kogu teatud alusel. Olgu uuritud homogeensete objektide kogumit, mida ühendab kvalitatiivse või kvantitatiivse iseloomuga ühine tunnus või omadus. Sellise komplekti üksikuid elemente nimetatakse selle liikmeteks. Rahvastiku liikmete koguarv on selle maht. Kutsutakse välja kõigi objektide komplekt, mida ühendab mingi atribuut üldine elanikkond. Valmistatud toodete kvalitatiivse hindamise käigus uuritakse näiteks elanike sissetulekuid, aktsiate turuväärtust või riigistandardist kõrvalekaldumist. Matemaatiline statistika on tihedalt seotud tõenäosusteooriaga ja toetub selle järeldustele. Eelkõige kontseptsioon elanikkonnast matemaatilises statistikas vastab mõistele elementaarsete sündmuste ruum tõenäosusteoorias. Kogu üldpopulatsiooni uurimine on enamasti võimatu või ebaotstarbekas oluliste materiaalsete kulude, uurimisobjekti kahjustamise või hävimise tõttu. Seega on võimatu saada objektiivset ja täielikku teavet kogu piirkonna elanike sissetulekute kohta; iga üksikelanik. Uurimisobjekti riknemise tõttu on võimatu saada usaldusväärset teavet näiteks teatud ravimite või toiduainete kvaliteedi kohta. Peamine ülesanne matemaatiline statistika on üldkogumi uurimine näidisandmete põhjal, olenevalt eesmärgist, ehk siis üldkogumi tõenäosuslike omaduste uurimine: jaotusseadus, arvtunnused jne. juhtimisotsuste tegemiseks ebakindluse tingimustes. Üks matemaatilise statistika meetodeid on proovivõtu meetod. Praktikas ei uurita enamasti mitte kogu populatsiooni, vaid sellest piiratud valimit. näidis(näidiskomplekt) on juhuslikult valitud objektide kogum. Valimimeetodi abil ei uurita mitte kogu populatsiooni, vaid valimit ( X 1 ,X 2 ,...,x n) piiratud arvu vaatluste tulemusena. Seejärel tehakse selle valimi tõenäosuslike omaduste järgi otsus kogu populatsiooni kohta teatud üldkogumi põhjal. Proovi saamiseks kasutatakse erinevaid proovivõtumeetodeid. Uuritavad objektid pärast uuringut võivad olla üldpopulatsioonis, mis vastab Näidist nimetatakse esindaja või esindaja,
kui ta taastoodab üldkogumit hästi, see tähendab, et valimi tõenäosuslikud omadused langevad kokku või on lähedased üldkogumi enda omadustele. Seega suureneb proovivõtumeetodi rakendamise tõhusus mitmel tingimusel, mille hulka kuuluvad järgmised: Uuritud näidisüksuste arv piisavalt järelduste tegemiseks, see tähendab, et valim on esinduslik või " esindaja». Seega määratakse tõenäosusteooria ja matemaatilise statistika seaduste abil kindlaks piisav arv osi partiis, mille kvaliteeti kontrollitakse (abielu). Näidisesemed peavad olema mitmekesine, juhuslikult võetud, need. põhimõtet tuleb austada randomiseerimine. Uuritud omadus –
tüüpiline, on tüüpiline uuritavate objektide komplekti kõikidele elementidele –
need. kogu elanikkonna jaoks. Uuritav omadus on märkimisväärne kõigi selle klassi elementide jaoks. Valimimeetodil uuritud statistilise üldkogumi märgi muutust nimetatakse variatsioon ja funktsiooni vaadeldavad väärtused x i
-
valik. Absoluutne sagedus
(sagedus või sagedus) valikud x i nimetatakse väärtust omavate üldkogumi liikmete arvuks (üld- või valim). x i(st see on osakeste arv i-
klass). Variandi järjestatud rühmitamine atribuudi individuaalsete väärtuste (või muutuste intervallide) järgi, s.t. nimetatakse kasvavas järjekorras järjestatud valikute jada variatsiooniline seeria. mis tahes funktsioon ( X 1 ,X 2 ,…,X n) vaatluste tulemustest X 1 ,X 2 ,…,X n uuritavat juhuslikku suurust nimetatakse statistika. Üldrahvastiku aktsepteeritud maht
määrama N,
selle absoluutsed sagedused on N i, näidissuurus - n,
selle absoluutsed sagedused on n i. See on ilmne Sageduse ja populatsiooni suuruse suhet nimetatakse suhteline sagedus või statistiline tõenäosus ja tähistatud W i
või Kui valikute arv on suur või valimi suuruse lähedal (diskreetse jaotusega) ja ka juhul, kui valim on moodustatud pidevast üldkogumist, siis variatsioonirida ei koostata üksikisiku kaupa - punkt - väärtused, kuid intervallidega rahvastiku väärtused. Kutsutakse välja tabeliga esindatud variatsiooniseeria, mis on koostatud rühmitamisprotseduuri abil intervall. Intervallide variatsiooni seeria koostamisel täidetakse tabeli esimene rida uuritava populatsiooni võrdse pikkusega väärtuste intervallidega, teine - vastavate absoluutsete või suhteliste sagedustega. Selle tulemusena mõnest üldisest elanikkonnast n vaatlustest saadi mahuproov P.
Statistiline jaotus
proovid nimetatakse valikute ja nende vastavate absoluutsete või suhteliste sageduste loendiks. Punktide variatsiooni seeria absoluutne
sagedused saab esitada tabelina: x i X k n i n k ja Punktide variatsiooni seeria suhtelised sagedused kujutatud tabeliga: x i X k ja Intervalljaotuse koostamisel kehtivad reeglid intervallide arvu või iga intervalli suuruse valimisel. Siin on kriteeriumiks optimaalne suhe: intervallide arvu suurenemisega paraneb esinduslikkus, kuid suureneb andmete hulk ja nende töötlemise aeg. Erinevus x max
-
x min suurima ja väikseima väärtuse vahel on variant nimega suures plaanis proovid. Intervallide arvu loendamiseks k Tavaliselt kasutatakse Sturgessi empiirilist valemit: k= 1+3,3221g n (3.1) (eeldades ümardamist lähima täisarvuni). Vastavalt sellele iga intervalli väärtus h saab arvutada järgmise valemi abil: x min = x max -
0,5h. Iga intervall peab sisaldama vähemalt viit valikut. Kui intervalli valikute arv on väiksem kui viis, on tavaks kombineerida külgnevaid intervalle. * Käesolev töö ei ole teaduslik töö, ei ole lõplik kvalifitseeriv töö ning on kogutud teabe töötlemise, struktureerimise ja vormistamise tulemus, mis on mõeldud kasutamiseks õppematerjalide allikana õppetöö iseseisvaks ettevalmistamiseks. Sissejuhatus. Viited. Matemaatilise statistika meetodid Sissejuhatus. Matemaatilise statistika põhimõisted. Psühholoogilise ja pedagoogilise uurimistöö tulemuste statistiline töötlemine. Viited. Matemaatilise statistika meetodid Sissejuhatus. Matemaatilise statistika põhimõisted. Psühholoogilise ja pedagoogilise uurimistöö tulemuste statistiline töötlemine. Viited. Sissejuhatus. Matemaatika rakendamine teistesse teadustesse on mõttekas ainult koosmõjus konkreetse nähtuse sügava teooriaga. Seda on oluline meeles pidada, et mitte sattuda lihtsasse valemimängu, millel pole tegelikku sisu. Akadeemik Yu.A. Metropoliit Psühholoogia ja pedagoogika teoreetilised uurimismeetodid võimaldavad paljastada uuritavate nähtuste kvalitatiivsed omadused. Need omadused on täielikumad ja sügavamad, kui kogutud empiirilist materjali töödeldakse kvantitatiivselt. Kvantitatiivsete mõõtmiste probleem psühholoogilise ja pedagoogilise uurimistöö raames on aga väga keeruline. See keerukus seisneb eelkõige pedagoogilise tegevuse ja selle tulemuste subjektiiv-põhjuslikus mitmekesisuses, mõõtmisobjektis, mis on pidevas liikumises ja muutumises. Samas on kvantitatiivsete näitajate juurutamine õppetöösse tänapäeval vajalik ja kohustuslik komponent pedagoogilise töö tulemuste kohta objektiivsete andmete saamiseks. Reeglina on neid andmeid võimalik saada nii pedagoogilise protsessi erinevate komponentide otsesel või kaudsel mõõtmisel kui ka selle adekvaatselt konstrueeritud matemaatilise mudeli asjakohaste parameetrite kvantifitseerimisel. Selleks kasutatakse psühholoogia ja pedagoogika probleemide uurimisel matemaatilise statistika meetodeid. Nende abil lahendatakse erinevaid ülesandeid: faktilise materjali töötlemine, uute, lisaandmete saamine, õppetöö teadusliku korralduse põhjendamine jm. 2. Matemaatilise statistika põhimõisted Paljude psühholoogiliste ja pedagoogiliste nähtuste analüüsimisel mängivad erakordselt olulist rolli keskmised väärtused, mis on kvalitatiivselt homogeense populatsiooni üldistatud tunnus teatud kvantitatiivse tunnuse järgi. Näiteks on võimatu arvutada ülikooli üliõpilaste keskmist eriala või keskmist rahvust, kuna tegemist on kvalitatiivselt heterogeensete nähtustega. Teisest küljest on võimalik ja vajalik keskmiselt määrata nende õppeedukuse (keskmise punktisumma), metoodiliste süsteemide ja tehnikate efektiivsuse jne numbriline tunnus. Psühholoogilises ja pedagoogilises uurimistöös kasutatakse tavaliselt erinevat tüüpi keskmisi: aritmeetiline keskmine, geomeetriline keskmine, mediaan, moodus ja teised. Levinumad on aritmeetiline keskmine, mediaan ja moodus. Aritmeetilist keskmist kasutatakse juhtudel, kui defineeriva omaduse ja selle tunnuse vahel on otseselt proportsionaalne seos (näiteks kui paraneb uuringurühma sooritus, paraneb iga selle liikme sooritus). Aritmeetiline keskmine on väärtuste summa jagamise jagatis nende arvuga ja arvutatakse järgmise valemiga: kus X on aritmeetiline keskmine; X1, X2, X3 ... Xn - üksikute vaatluste tulemused (tehnikad, tegevused), n - vaatluste arv (meetodid, toimingud), Kõikide vaatluste (tehnikad, tegevused) tulemuste summa. Mediaan (Me) on keskmise positsiooni mõõt, mis iseloomustab objekti väärtust järjestatud (suurendamise või vähenemise alusel ehitatud) skaalal, mis vastab uuritava populatsiooni keskkohale. Mediaani saab määrata järguliste ja kvantitatiivsete tunnuste jaoks. Selle väärtuse asukoht määratakse järgmise valemiga: Keskmine asukoht = (n + 1) / 2 Näiteks. Uuringu tulemuste kohaselt leiti, et: – “suurepärased” õpilased – 5 inimest katses osalenutest; – “hästi” õpib 18 inimest; - "rahuldava" jaoks - 22 inimest; - "mitterahuldava" jaoks - 6 inimest. Kuna katses osales kokku N = 54 inimest, võrdub valimi keskmine inimestega. Siit järeldatakse, et üle poole õpilastest õpib alla „hea“ hinde, st mediaan on rohkem kui „rahuldav“, kuid vähem kui „hea“ (vt joonist). Režiim (Mo) on teiste väärtuste hulgas kõige levinum tüüpiline tunnusväärtus. See vastab kõrgeima sagedusega klassile. Seda klassi nimetatakse modaalväärtuseks. Näiteks. Kui küsimustiku küsimus: "märkida võõrkeele oskuse aste", jagati vastused: 1 - ladus - 25 2 - Ma tean piisavalt, et suhelda - 54 3 - Ma tean, kuid mul on suhtlemisraskusi - 253 4 – saan raskustega aru – 173 5 - ei tea - 28 Ilmselt on siin kõige tüüpilisem tähendus "ma tean, aga mul on raskusi suhtlemisega", mis on modaalne. Seega on režiim -253. Matemaatiliste meetodite kasutamisel psühholoogilistes ja pedagoogilistes uuringutes omistatakse suurt tähtsust dispersiooni ja ruutkeskmise (standardhälbe) arvutamisele. Dispersioon on võrdne optsioonide väärtuste keskmisest kõrvalekallete keskmise ruuduga. See toimib uuritava muutuja väärtuste (näiteks õpilaste hinnete) keskväärtuse ümber hajutamise üksikute tulemuste ühe tunnusena. Dispersiooni arvutamisel määratakse: kõrvalekalded keskmisest väärtusest; määratud hälbe ruut; hälbe ruutude summa ja hälbe ruudu keskmine väärtus (vt tabel 6.1). Dispersiooni väärtust kasutatakse erinevates statistilistes arvutustes, kuid see pole otseselt jälgitav. Vaadeldava muutuja sisuga otseselt seotud suurus on standardhälve. Tabel 6.1 Dispersiooni arvutamise näide Tähendus indikaator Hälve keskmisest kõrvalekalded 2
– 3 = – 1 Standardhälve kinnitab aritmeetilise keskmise tüüpilisust ja indikatiivsust, peegeldab märkide arvväärtuste kõikumise mõõdet, millest tuletatakse keskmine väärtus. See võrdub dispersiooni ruutjuurega ja määratakse järgmise valemiga: kus: - ruutkeskmine. Väikese arvu vaatluste (toimingute) korral - vähem kui 100 - tuleks valemi väärtusesse panna mitte "N", vaid "N - 1". Aritmeetiline keskmine ja keskmine ruut on uuringu käigus saadud tulemuste peamised omadused. Need võimaldavad teil andmeid kokku võtta, võrrelda, tuvastada ühe psühholoogilise ja pedagoogilise süsteemi (programmi) eelised teise ees. Ruutkeskmist (standardhälvet) kasutatakse laialdaselt erinevate tunnuste hajuvuse mõõtmiseks. Uuringu tulemuste hindamisel on oluline määrata juhusliku suuruse dispersioon keskväärtuse ümber. Seda dispersiooni kirjeldatakse Gaussi seaduse (juhusliku suuruse tõenäosuse normaaljaotuse seadus) abil. Seaduse olemus seisneb selles, et teatud atribuudi mõõtmisel antud elementide kogumis esineb alati mõlemas suunas paljudel kontrollimatutel põhjustel kõrvalekaldeid normist ja mida suuremad on kõrvalekalded, seda harvemini neid esineb. Andmete edasisel töötlemisel võib ilmneda: variatsioonikoefitsient (stabiilsus) uuritav nähtus, mis on standardhälbe protsent aritmeetilisest keskmisest; kaldsuse mõõt, mis näitab, millises suunas on suunatud valdav hulk kõrvalekaldeid; jaheduse mõõt, mis näitab juhusliku suuruse väärtuste kogunemise astet keskmise ümber jne. Kogu see statistika aitab täpsemalt tuvastada uuritavate nähtuste tunnuseid. Muutujate vahelise seose mõõtmed. Nimetatakse seoseid (sõltuvusi) statistikas kahe või enama muutuja vahel korrelatsioon. Selle hindamiseks kasutatakse korrelatsioonikordaja väärtust, mis on selle seose astme ja ulatuse mõõt. Korrelatsioonikordajaid on palju. Vaatleme ainult osa neist, mis arvestavad muutujate vahelise lineaarse seose olemasolu. Nende valik sõltub muutujate mõõtmise skaaladest, mille omavahelist seost tuleb hinnata. Pearsoni ja Spearmani koefitsiente kasutatakse kõige sagedamini psühholoogias ja pedagoogikas. Kaaluge korrelatsioonikoefitsientide väärtuste arvutamist konkreetsetel näidetel. Näide 1. Mõõdetakse kahte võrreldavat muutujat X (perekonnaseis) ja Y (kõrgkoolist väljaarvamine) dihhotoomsel skaalal (tiitliskaala erijuhtum). Seose määramiseks kasutame Pearsoni koefitsienti. Juhtudel, kui ei ole vaja arvutada muutujate X ja Y erinevate väärtuste esinemissagedust, on mugav korrelatsioonikoefitsient arvutada juhuslikkuse tabeli abil (vt tabelid 6.2, 6.3, 6.4), näidates numbrit. kahe muutuja (tunnuse) väärtuspaaride ühisesinemistest . A - juhtude arv, mil muutuja X väärtus on võrdne nulliga ja samal ajal on muutuja Y väärtus ühega; B - juhtude arv, kui muutujatel X ja Y on samaaegselt väärtused ühega; C on juhtude arv, kui muutujatel X ja Y on samaaegselt väärtused nulliga; D on kordade arv, mil muutuja X väärtus on võrdne ühega ja samal ajal on muutuja Y väärtus nulliga. Tabel 6.2 Üldine situatsioonitabel Funktsioon X Üldiselt on Pearsoni korrelatsioonikordaja valem dihhotoomsete andmete jaoks Tabel 6.3 Näide andmetest dihhotoomses skaalas Asendame vaadeldavale näitele vastava juhuslikkuse tabeli (vt tabel 6.4) andmed valemiga: Seega on Pearsoni korrelatsioonikoefitsient valitud näite puhul 0,32 ehk seos üliõpilaste perekonnaseisu ja ülikoolist väljaarvamise faktide vahel on ebaoluline. Näide 2. Kui mõlemat muutujat mõõdetakse järjestusskaaladel, siis kasutatakse seose mõõduna Spearmani auaste korrelatsioonikordajat (Rs). See arvutatakse valemi järgi kus Rs on Spearmani astme korrelatsioonikordaja; Di on erinevus võrreldavate objektide järjestuste vahel; N on võrreldavate objektide arv. Spearmani koefitsiendi väärtus varieerub vahemikus -1 kuni + 1. Esimesel juhul on analüüsitavate muutujate vahel ühemõtteline, kuid vastupidiselt suunatud seos (ühe väärtuste suurenemisega teise väärtused suurenevad vähenemine). Teises, ühe muutuja väärtuste kasvuga, suureneb teise muutuja väärtus proportsionaalselt. Kui Rs väärtus on võrdne nulliga või selle väärtus on sellele lähedane, siis pole muutujate vahel olulist seost. Spearmani koefitsiendi arvutamise näitena kasutame tabeli 6.5 andmeid. Tabel 6.5 Koefitsiendi väärtuse arvutamise andmed ja vahetulemused astme korrelatsioon Rs Omadused Auastmed, mille määrab ekspert Aste erinevus järgu erinevus ruudus –1 Järjevahede ruudu summa Di = 22 Asendage näidisandmed Smirmani koefitsiendi valemiga: Arvutustulemused lubavad väita, et vaadeldavate muutujate vahel on üsna väljendunud seos. Teadusliku hüpoteesi statistiline kontrollimine. Eksperimentaalse mõju statistilise usaldusväärsuse tõestus erineb oluliselt matemaatika ja formaalse loogika tõestamisest, kus järeldused on oma olemuselt universaalsemad: statistilised tõestused ei ole nii ranged ja lõplikud - need võimaldavad alati järeldustes vigade tegemise ohtu. ja seetõttu ei tõestata ühe või teise paikapidavust lõplikult statistiliste meetoditega.järeldus, vaid näidatakse konkreetse hüpoteesi aktsepteerimise tõenäosuse mõõt. Pedagoogiline hüpotees (teaduslik oletus ühe või teise meetodi eelisest vms) tõlgitakse statistilise analüüsi käigus statistikateaduse keelde ja sõnastatakse ümber vähemalt kahes statistilises hüpoteesis. Esimest (peamist) nimetatakse nullhüpotees(H 0), milles uurija räägib oma lähtepositsioonist. Ta näib (a priori) deklareerivat, et (tema, tema kolleegide või vastaste soovitatud) uuel meetodil pole eeliseid ja seetõttu on teadlane juba algusest peale psühholoogiliselt valmis võtma ausat teaduslikku seisukohta: uued ja vanad meetodid kuulutatakse võrdseks nulliga. Teises alternatiivne hüpotees(H 1) tehakse eeldus uue meetodi eelise kohta. Mõnikord esitatakse sobiva tähistusega mitu alternatiivset hüpoteesi. Näiteks hüpotees vana meetodi eelisest (H 2). Alternatiivseid hüpoteese aktsepteeritakse siis ja ainult siis, kui nullhüpotees lükatakse ümber. See juhtub juhtudel, kui erinevused näiteks katse- ja kontrollrühmade aritmeetilistes keskmistes on nii olulised (statistiliselt olulised), et vearisk nullhüpoteesi tagasilükkamisel ja alternatiivi aktsepteerimisel ei ületa ühte kolmest aktsepteeritud. olulisuse tasemed statistiline järeldus: - esimene tase - 5% (teadustekstides kirjutatakse mõnikord p \u003d 5% või a? 0,05, kui see on esitatud aktsiates), kus järelduses on eksimise oht lubatud viiel juhul sajast teoreetiliselt võimalikust sarnasest katsed iga katse jaoks rangelt juhusliku subjektide valikuga; - teine tase - 1%, st vastavalt on eksimise oht lubatud ainult ühel juhul sajast (a? 0,01, samade nõuetega); - kolmas tase - 0,1%, st eksimise oht on lubatud ainult ühel juhul tuhandest (a? 0,001). Viimane olulisuse tase seab väga kõrged nõudmised katsetulemuste usaldusväärsuse põhjendamisele ja seetõttu kasutatakse seda harva. Katse- ja kontrollrühma aritmeetiliste keskmiste võrdlemisel on oluline mitte ainult kindlaks teha, kumb keskmine on suurem, vaid ka seda, kui palju suurem. Mida väiksem on erinevus nende vahel, seda vastuvõetavam on nullhüpotees statistiliselt oluliste (oluliste) erinevuste puudumise kohta. Erinevalt tavateadvuse tasandil mõtlemisest, mis kipub kogemuse tulemusena saadud keskmiste erinevust tajuma faktina ja järelduste alusena, ei kiirusta statistilise järeldamise loogikat tundev õpetaja-teadur sellises. juhtudel. Tõenäoliselt teeb ta eelduse, et erinevused on juhuslikud, esitab nullhüpoteesi oluliste erinevuste puudumise kohta katse- ja kontrollrühmade tulemustes ning alles pärast nullhüpoteesi ümberlükkamist aktsepteerib alternatiivset hüpoteesi. Seega kandub küsimus erinevustest teadusliku mõtlemise raames teisele tasandile. Asi pole mitte ainult erinevustes (need on peaaegu alati olemas), vaid nende erinevuste suuruses ja sellest tulenevalt - selle erinevuse ja piiri kindlaksmääramises, mille järel võib öelda: jah, erinevused ei ole juhuslikud, need on statistilised. märkimisväärne, mis tähendab, et nende kahe rühma katsealused ei kuulu pärast katset enam ühte (nagu varem), vaid kahte erinevasse üldpopulatsiooni ning nendesse populatsioonidesse potentsiaalselt kuuluvate õpilaste valmisoleku tase erineb oluliselt. Nende erinevuste piiride näitamiseks on nn üldparameetrite hinnangud. Mõelge konkreetse näite (vt tabel 6.6) abil, kuidas saab matemaatilist statistikat kasutada nullhüpoteesi ümberlükkamiseks või kinnitamiseks. Oletame, et on vaja kindlaks teha, kas õpilaste rühmategevuse tulemuslikkus sõltub inimestevaheliste suhete arengutasemest õpperühmas. Nullhüpoteesina esitatakse eeldus, et sellist sõltuvust ei eksisteeri ja alternatiivina on sõltuvus olemas. Sel eesmärgil võrreldakse tegevuste efektiivsuse tulemusi kahes rühmas, millest üks toimib antud juhul katserühmana ja teine kontrollrühmana. Et teha kindlaks, kas esimese ja teise rühma tulemusnäitajate keskmiste väärtuste erinevus on oluline (oluline), on vaja arvutada selle erinevuse statistiline olulisus. Selleks saab kasutada t – õpilase kriteeriumi. See arvutatakse järgmise valemiga: kus X 1 ja X 2 - rühmade 1 ja 2 muutujate aritmeetiline keskmine; M 1 ja M 2 on keskmiste vigade väärtused, mis arvutatakse järgmise valemiga: kus on valemiga (2) arvutatud ruutkeskmine. Määrame esimese rea (katserühm) ja teise rea (kontrollrühm) vead: Leiame t väärtuse - kriteeriumi valemiga: Pärast t-kriteeriumi väärtuse arvutamist on vaja spetsiaalse tabeli abil määrata katse- ja kontrollrühma keskmiste tulemusnäitajate erinevuste statistilise olulisuse tase. Mida suurem on t-kriteeriumi väärtus, seda suurem on erinevuste olulisus. Selleks võrdleme arvutatud t tabeli t-ga. Tabeliväärtus valitakse, võttes arvesse valitud usaldustaset (p = 0,05 või p = 0,01) ja sõltuvalt ka vabadusastmete arvust, mis leitakse valemiga: kus U on vabadusastmete arv; N 1 ja N 2 - mõõtmiste arv esimeses ja teises reas. Meie näites U = 7 + 7 -2 = 12. Tabel 6.6 Statistilise olulisuse arvutamise andmed ja vahetulemused Keskmised erinevused Eksperimentaalne rühm Kontrollgrupp Tulemuslikkuse väärtus Tabeli t puhul leiame, et tabeli t väärtus. = 3,055 ühe protsendi tasemel (lk Õpetaja-teadur peaks aga meeles pidama, et keskmiste väärtuste erinevuse statistilise olulisuse olemasolu on oluline, kuid mitte ainus argument nähtuste või muutujate vahelise seose (sõltuvuse) olemasolu või puudumise kasuks. . Seetõttu on võimaliku seose kvantitatiivseks või sisuliseks põhjendamiseks kaasata muid argumente. Andmete analüüsi mitmemõõtmelised meetodid. Suure hulga muutujate vahelise seose analüüs viiakse läbi mitme muutujaga statistilise töötlemise meetodite abil. Selliste meetodite rakendamise eesmärk on muuta nähtavaks peidetud mustrid, tuua esile kõige olulisemad muutujatevahelised seosed. Selliste mitmemõõtmeliste statistiliste meetodite näited on järgmised: - faktoranalüüs; – klasteranalüüs; – dispersioonanalüüs; - regressioonanalüüs; – latentne struktuurianalüüs; – mitmemõõtmeline skaleerimine ja muud. Faktoranalüüs on tegurite tuvastamine ja tõlgendamine. Tegur on üldistatud muutuja, mis võimaldab teil osa teabest ahendada, st esitada seda arusaadaval kujul. Näiteks isiksuse faktoriteooria identifitseerib mitmeid üldistatud käitumisomadusi, mida antud juhul nimetatakse isiksuseomadusteks. klastri analüüs võimaldab esile tõsta juhtivat tunnust ja funktsioonisuhete hierarhiat. Dispersioonanalüüs– statistiline meetod, mida kasutatakse vaadeldava tunnuse varieeruvuse ühe või mitme samaaegselt toimiva ja sõltumatu muutuja uurimiseks. Selle eripära on see, et vaadeldav tunnus saab olla ainult kvantitatiivne, samas kui selgitavad tunnused võivad olla nii kvantitatiivsed kui ka kvalitatiivsed. Regressioonanalüüs võimaldab tuvastada resultantatribuudi (selgitatud) muutuste keskmise väärtuse kvantitatiivse (numbrilise) sõltuvuse muutustest ühes või mitmes atribuudis (selgitavad muutujad). Reeglina kasutatakse seda tüüpi analüüsi siis, kui on vaja välja selgitada, kui palju muutub ühe atribuudi keskmine väärtus, kui teine atribuut muutub ühe võrra. Latentne struktuurianalüüs kujutab analüütiliste ja statistiliste protseduuride kogumit peidetud muutujate (tunnuste) tuvastamiseks, samuti nendevaheliste seoste sisemist struktuuri. See võimaldab uurida sotsiaalpsühholoogiliste ja pedagoogiliste nähtuste otseselt mittejälgitavate tunnuste keeruliste vastastikuste seoste ilminguid. Varjatud analüüs võib olla nende suhete modelleerimise aluseks. Mitmemõõtmeline skaleerimine annab visuaalse hinnangu mõne objekti sarnasusele või erinevusele, mida kirjeldatakse suure hulga erinevate muutujatega. Need erinevused on esitatud kui kaugus hinnanguliste objektide vahel mitmemõõtmelises ruumis. 3. Psühholoogilise ja pedagoogilise tulemuste statistiline töötlemine uurimine Igas uuringus on alati oluline tagada uurimisobjektide massiline iseloom ja esinduslikkus (representatiivsus). Selle probleemi lahendamiseks kasutavad nad tavaliselt uuritavate objektide (vastajate rühmade) minimaalse suuruse arvutamiseks matemaatilisi meetodeid, et selle põhjal saaks teha objektiivseid järeldusi. Primaarsete üksuste katvuse täielikkuse astme järgi jagab statistika uuringud pidevateks, mil uuritakse uuritava nähtuse kõiki ühikuid, ja selektiivseks, kui uuritakse ainult osa huvipakkuvast populatsioonist, mis on võetud mingi tunnuse järgi. . Teadlasel ei ole alati võimalust uurida kogu nähtuste kogumit, kuigi selle poole tuleks pidevalt püüelda (pole piisavalt aega, vahendeid, vajalikke tingimusi jne); teisest küljest pole sageli pidevat uuringut lihtsalt vaja, kuna järeldused on piisavalt täpsed pärast teatud osa esmaste üksuste uurimist. Selektiivse uurimismeetodi teoreetiliseks aluseks on tõenäosusteooria ja suurte arvude seadus. Selleks, et uuringus oleks piisavalt fakte, tähelepanekuid, kasutatakse piisavalt suurte arvude tabelit. Sel juhul peab uurija kindlaks määrama tõenäosuse suuruse ja lubatud vea suuruse. Näiteks ei tohiks lubatav viga järeldustes, mis tuleks vaatluste tulemusel teha, võrreldes teoreetiliste eeldustega ületada 0,05 nii positiivselt kui ka negatiivselt (teisisõnu võime teha mitte rohkem kui 5 vea juhtudest 100-st). Seejärel leiame piisavalt suurte arvude tabeli järgi (vt tabel 6.7), et õige järelduse saab teha 9 juhul 10-st, kui vaatluste arv on vähemalt 270, 99 juhul 100-st, kui on vähemalt 663 vaatlust jne. e. Seega, kui täpsus ja tõenäosus, millega me peaksime järeldusi tegema, suureneb, suureneb ka vajalike vaatluste arv. Kuid psühholoogilises ja pedagoogilises uuringus ei tohiks see olla ülemäära suur. 300–500 vaatlust on sageli kindlate järelduste tegemiseks täiesti piisav. See valimi suuruse määramise meetod on kõige lihtsam. Matemaatilises statistikas on ka keerukamad meetodid vajalike valimihulkade arvutamiseks, mida on üksikasjalikult käsitletud erialakirjanduses. Massi iseloomu nõuete järgimine ei taga aga veel järelduste usaldusväärsust. Need on usaldusväärsed, kui vaatluseks valitud ühikud (vestlused, katsed jne) on uuritava nähtuste klassi jaoks piisavalt esindavad. Tabel 6.7 Piisavalt suurte numbrite lühike tabel Väärtus tõenäosused Lubatud Vaatlusüksuste esinduslikkuse tagab eelkõige nende juhuslik valik juhuslike arvude tabelite abil. Oletame, et olemasolevast 200-st on vaja määrata massikatse läbiviimiseks 20 treeningrühma. Selleks koostatakse kõigi rühmade nimekiri, mis on nummerdatud. Seejärel tõmmatakse juhuslike arvude tabelist teatud intervalliga 20 numbrit, alustades mis tahes arvust. Need 20 juhuslikku arvu määravad numbreid jälgides rühmad, mida uurija vajab. Objektide juhuslik valik üld(üld)populatsioonist annab alust väita, et üksuste valimipopulatsiooni uurimisel saadud tulemused ei erine järsult nendest, mis oleksid kättesaadavad kogu üldkogumi uurimisel. ühikut. Psühholoogilise ja pedagoogilise uurimistöö praktikas ei kasutata mitte ainult lihtsaid juhuslikke valikuid, vaid ka keerukamaid valikumeetodeid: stratifitseeritud juhuslik valik, mitmeastmeline valik jne. Matemaatilised ja statistilised uurimismeetodid on ka vahendid uue faktilise materjali saamiseks. Selleks kasutatakse ankeediküsimuse informatiivsust suurendavaid mallivõtteid ja skaleerimist, mis võimaldab täpsemalt hinnata nii uurija kui katsealuste tegevust. Kaalud tekkisid vajadusest objektiivselt ja täpselt diagnoosida ja mõõta teatud psühholoogiliste ja pedagoogiliste nähtuste intensiivsust. Skaleerimine võimaldab nähtusi sujuvamaks muuta, igaüht neist kvantifitseerida, määrata uuritava nähtuse madalaim ja kõrgeim tase. Nii et kuulajate kognitiivseid huvisid uurides võib paika panna nende piirid: väga suur huvi – väga nõrk huvi. Nende piiride vahele viige sisse mitmeid samme, mis loovad kognitiivsete huvide skaala: väga suur huvi (1); suur huvi (2); keskmine (3); nõrk (4); väga nõrk (5). Psühholoogilises ja pedagoogilises uurimistöös kasutatakse erinevat tüüpi skaalasid, nt. a) Kolmemõõtmeline skaala Väga aktiivne………………..10 Aktiivne………………………………5 Passiivne …………………………….0 b) Mitmemõõtmeline skaala Väga aktiivne……………………..8 Keskmiselt aktiivne…………………….6 Mitte liiga aktiivne……………4 Passiivne …………………………..2 Täiesti passiivne……………0 c) Kahepoolne skaala. Väga huvitatud……………..10 Piisavalt huvitatud…………5 Ükskõikne……………………….0 Ei ole huvitatud……………………..5 Absoluutselt puudub huvi………10 Numbrilised hindamisskaalad annavad igale elemendile kindla numbrilise tähistuse. Niisiis, kui analüüsida õpilaste suhtumist õppesse, visadust töös, koostöövalmidust jne. saate teha numbrilise skaala järgmiste näitajate põhjal: 1 - mitterahuldav; 2 - nõrk; 3 - keskmine; 4 on üle keskmise, 5 on palju üle keskmise. Sel juhul on skaala järgmine (vt tabel 6.8): Tabel 6.8 Kui numbriline skaala on bipolaarne, kasutatakse bipolaarset järjestust, mille keskel on null: Distsipliin Distsiplineerimatus Hääldatud 5 4 3 2 1 0 1 2 3 4 5 Ei hääldata Hindamisskaalasid saab kuvada graafiliselt. Sel juhul väljendavad nad kategooriaid visuaalsel kujul. Veelgi enam, skaala iga jaotust (astet) iseloomustatakse verbaalselt. Vaadeldavatel meetoditel on oluline roll saadud andmete analüüsimisel ja üldistamisel. Need võimaldavad luua erinevaid seoseid, seoseid faktide vahel, tuvastada psühholoogiliste ja pedagoogiliste nähtuste arengu suundumusi. Seega aitab matemaatilise statistika rühmitamise teooria välja selgitada, millised faktid kogutud empiirilisest materjalist on võrreldavad, mille alusel neid õigesti rühmitada ja millise usaldusväärsusega need on. Kõik see võimaldab vältida meelevaldseid manipuleerimisi faktidega ja määrata nende töötlemise programm. Sõltuvalt eesmärkidest ja eesmärkidest kasutatakse tavaliselt kolme tüüpi rühmitusi: tüpoloogilist, variatsioonilist ja analüütilist. Tüpoloogiline rühmitus kasutatakse siis, kui on vaja saadud faktiline materjal jagada kvalitatiivselt homogeenseteks üksusteks (distsipliinirikkumiste arvu jaotus erinevate õpilaste kategooriate vahel, nende kehaliste harjutuste tulemusnäitajate jaotus õppeaastate lõikes jne). Vajadusel rühmitage materjal vastavalt muutuva (muutuva) atribuudi väärtusele - õpilaste rühmade jaotus sooritustaseme, ülesannete täitmise protsendi, kehtestatud korra sarnaste rikkumiste jms järgi. – kehtib variatsiooniline rühmitus, mis võimaldab järjekindlalt hinnata uuritava nähtuse struktuuri. Rühmitamise analüütiline vaade aitab tuvastada uuritavate nähtuste seost (õpilaste ettevalmistusastme sõltuvus erinevatest õppemeetoditest, sooritatavate ülesannete kvaliteet temperamendist, võimetest jne), nende vastastikust sõltuvust ja vastastikust sõltuvust täpses arvestuses. Kui oluline on teadlase töö kogutud andmete rühmitamisel, annab tunnistust asjaolu, et antud töö vead devalveerivad kõige põhjalikuma ja sisukama informatsiooni. Praegu on sotsioloogias kõige põhjalikumalt arenenud rühmitamise, tüpoloogia ja klassifitseerimise matemaatilised alused. Kaasaegseid sotsioloogiliste uuringute tüpoloogia ja klassifitseerimise käsitlusi ja meetodeid saab edukalt rakendada psühholoogias ja pedagoogikas. Uuringu käigus kasutatakse andmete lõpliku üldistamise meetodeid. Üks neist on tabelite koostamise ja uurimise tehnika. Ühe statistilise väärtuse kohta andmete kokkuvõtte koostamisel moodustatakse selle väärtuse väärtusest jaotusrida (variatsioonirea). Sellise seeria näide (vt tabel 6.9) on kokkuvõte andmetest 500 näo rinna ümbermõõdu kohta. Tabel 6.9 Kahe või enama statistilise väärtuse samaaegne andmete kokkuvõte hõlmab jaotustabeli koostamist, mis näitab ühe staatilise väärtuse väärtuste jaotust vastavalt väärtustele, mida teised väärtused võtavad. Näitena on toodud tabel 6.10, mis on koostatud statistiliste andmete põhjal nende inimeste rinnaümbermõõtu ja kaalu kohta. Tabel 6.10 Rinnaümbermõõt cm Jaotustabel annab aimu seostest ja seostest, mis kahe väärtuse vahel eksisteerivad, nimelt: väikese kaalu korral asuvad sagedused tabeli vasakpoolses ülemises veerandis, mis näitab väikese rinnaga inimeste ülekaalu. ümbermõõt. Kui kaal suureneb keskmise väärtuse suunas, liigub sagedusjaotus plaadi keskele. See näitab, et keskmisele kaalule lähemal olevate inimeste rinnaümbermõõt on samuti keskmisele lähedane. Kaalu edasise suurenemisega hakkavad sagedused hõivama plaadi alumist paremat veerandit. See viitab sellele, et keskmisest suurema kehakaaluga inimesel on ka rindkere ümbermõõt üle keskmise mahu. Tabelist järeldub, et loodud seos ei ole range (funktsionaalne), vaid tõenäosuslik, kui ühe suuruse väärtuste muutumisel muutub teine trendina, ilma jäiga ühemõttelise sõltuvuseta. Selliseid seoseid ja sõltuvusi leidub sageli psühholoogias ja pedagoogikas. Praegu väljendatakse neid tavaliselt korrelatsiooni- ja regressioonanalüüsi abil. Variatsioonilised seeriad ja tabelid annavad aimu nähtuse staatikast, dünaamikat saab aga näidata arendusseeriatena, kus esimene rida sisaldab järjestikuseid etappe või ajavahemikke ja teine - uuritud statistiliste näitajate väärtusi. nendel etappidel saadud väärtus. Seega ilmneb uuritava nähtuse kasv, vähenemine või perioodilised muutused, ilmnevad selle tendentsid ja mustrid. Tabeleid saab täita absoluutväärtustega või koondarvudega (keskmine, suhteline). Statistilise töö tulemused - lisaks tabelitele on need sageli kujutatud graafiliselt diagrammide, jooniste jms kujul. Statistiliste väärtuste graafilise esitamise peamised viisid on: punktide meetod, sirgjoonte meetod ja ristkülikute meetod. Need on lihtsad ja igale uurijale kättesaadavad. Nende kasutamise tehnika on koordinaattelgede joonistamine, skaala seadistamine ja segmentide (punktide) tähistamise väljastamine horisontaal- ja vertikaalteljel. Diagrammid, mis kujutavad ühe statistilise suuruse väärtuste jaotusridu, võimaldavad koostada jaotuskõveraid. Kahe (või enama) statistilise suuruse graafiline esitus võimaldab moodustada teatud kõvera pinna, mida nimetatakse jaotuspinnaks. Mitmed graafilise teostuse arengud moodustavad arengukõveraid. Statistilise materjali graafiline esitus võimaldab tungida sügavamale digitaalsete väärtuste tähendusse, tabada nende vastastikust sõltuvust ja uuritava nähtuse tunnuseid, mida tabelis on raske märgata. Uurija vabaneb tööst, mida ta peaks tegema, et arvude rohkusega toime tulla. Tabelid ja graafikud on olulised, kuid alles esimesed sammud statistiliste suuruste uurimisel. Peamine meetod on analüütiline, mis töötab matemaatiliste valemitega, mille abil tuletatakse nn üldistavad näitajad ehk võrreldaval kujul antud absoluutväärtused (suhtelised ja keskmised väärtused, saldod ja indeksid). Nii määratakse suhteliste väärtuste (protsendide) abil analüüsitud populatsioonide kvalitatiivsed tunnused (näiteks suurepäraste õpilaste suhe õpilaste koguarvusse; vigade arv keeruliste seadmetega töötamisel. õpilaste vaimse ebastabiilsuse, vigade koguarvuni jne). See tähendab, et ilmnevad seosed: osad tervikuga (erikaal), terminid summaga (hulga struktuur), hulga üks osa selle teise osaga; mis tahes muutuste dünaamika iseloomustamine ajas jne. Nagu näha, viitab isegi kõige üldisem ettekujutus statistilise arvutuse meetodite kohta, et neil meetoditel on suur potentsiaal empiirilise materjali analüüsimisel ja töötlemisel. Muidugi suudab matemaatiline aparaat kiretult töödelda kõike, mida uurija sellesse paneb, nii usaldusväärseid andmeid kui ka subjektiivseid oletusi. Seetõttu on matemaatilise aparaadi täiuslik valdamine akumuleeritud empiirilise materjali ühtseks töötlemiseks uuritava nähtuse kvalitatiivsete omaduste põhjaliku tundmisega igale uurijale vajalik. Ainult sel juhul on võimalik valida kvaliteetne objektiivne faktiline materjal, selle kvalifitseeritud töötlemine ja usaldusväärsete lõppandmete saamine. See on psühholoogia ja pedagoogika probleemide uurimise kõige sagedamini kasutatavate meetodite lühikirjeldus. Tuleb rõhutada, et ükski vaadeldavatest meetoditest ei saa iseenesest väita, et see on universaalne, et tagada saadud andmete objektiivsus. Seega on subjektiivsuse elemendid vastajate intervjueerimisel saadud vastustes ilmsed. Vaatluste tulemused ei ole reeglina vabad uurija enda subjektiivsetest hinnangutest. Erinevatest dokumentidest võetud andmed nõuavad selle dokumentatsiooni (eelkõige isiklikud dokumendid, kasutatud dokumendid jne) autentsuse üheaegset kontrollimist. Seetõttu peaks iga teadlane püüdma ühelt poolt täiustada mis tahes konkreetse meetodi rakendamise tehnikat ja teiselt poolt erinevate meetodite kompleksset, vastastikku kontrollivat kasutamist sama probleemi uurimiseks. Kogu meetodite süsteemi omamine võimaldab välja töötada ratsionaalse uurimismetoodika, seda selgelt korraldada ja läbi viia ning saada olulisi teoreetilisi ja praktilisi tulemusi. Viited. Shevandrin N.I. Sotsiaalpsühholoogia hariduses: õpik. 1. osa. Sotsiaalpsühholoogia kontseptuaalsed ja rakenduslikud alused. – M.: VLADOS, 1995. 2. Davõdov V.P. Pedagoogilise uurimistöö metoodika, metoodika ja tehnoloogia alused: Teaduslik ja metoodiline käsiraamat. - M .: FSB akadeemia, 1997. JUHUSLIKUD VÄÄRTUSED JA NENDE JAOTAMISE SEADUSED. Juhuslik nimetatakse suuruseks, mis võtab väärtusi sõltuvalt juhuslike asjaolude kombinatsioonist. Eristama diskreetne
ja juhuslikult pidev
kogused. Diskreetne Kogust nimetatakse siis, kui see võtab loendatava väärtuste hulga. ( Näide: patsientide arv arstikabinetis, tähtede arv leheküljel, molekulide arv antud mahus). pidev nimetatakse suuruseks, mis võib teatud intervalli jooksul väärtusi võtta. ( Näide:õhutemperatuur, kehakaal, inimese pikkus jne) jaotusseadus Juhuslik suurus on selle suuruse võimalike väärtuste kogum ja nendele väärtustele vastavad tõenäosused (või esinemissagedused). NÄIDE: JUHUSLIKUTE VÄÄRTUSTE ARVULISED KARAKTERISTIKUD. Paljudel juhtudel koos juhusliku suuruse jaotusega või selle asemel saab nende suuruste kohta teavet anda numbriliste parameetritega nn. juhusliku suuruse arvkarakteristikud
. Kõige sagedamini kasutatavad neist: 1
.Oodatud väärtus -
juhusliku suuruse (keskmine väärtus) on kõigi selle võimalike väärtuste ja nende väärtuste tõenäosuste korrutised: 2
.Dispersioon
juhuslik muutuja: 3
.Standardhälve
: KOLME SIGMA reegel - kui juhuslik suurus on jaotatud normaalseaduse järgi, siis selle väärtuse hälve absoluutväärtuse keskmisest väärtusest ei ületa kolmekordset standardhälvet ZON GAUSS – NORMAALNE JAOTUSSEADUS Sageli on väärtused jagatud tavaline seadus
(Gaussi seadus). peamine omadus
: see on piirav seadus, millele lähenevad teised levitamisseadused. Juhuslik muutuja on tavaliselt jaotatud, kui see tõenäosustihedus
paistab nagu: M(X)- juhusliku suuruse matemaatiline ootus; s- standardhälve. Tõenäosuse tihedus(jaotusfunktsioon) näitab, kuidas intervalliga seotud tõenäosus muutub dx
juhuslik muutuja, olenevalt muutuja enda väärtusest: MATEMAATILISE STATISTIKA PÕHIMÕISTED Matemaatika statistika- rakendusmatemaatika haru, mis külgneb vahetult tõenäosusteooriaga. Peamine erinevus matemaatilise statistika ja tõenäosusteooria vahel seisneb selles, et matemaatilises statistikas ei arvestata jaotusseaduste ja juhuslike suuruste arvuliste karakteristikutega seotud toiminguid, vaid ligikaudseid meetodeid nende seaduste ja arvuliste tunnuste leidmiseks katsetulemuste põhjal. Põhimõisted matemaatiline statistika on järgmine: 1.
Üldrahvastik;
2.
näidis;
3.
variatsiooniseeria;
4.
mood;
5.
mediaan;
6.
protsentiil,
7.
sageduse hulknurk,
8.
tulpdiagramm.
Rahvaarv- suur statistiline üldkogum, millest valitakse välja osa uurimisobjekte (Näide: kogu piirkonna elanikkond, linna üliõpilased jne) Valim (valimi populatsioon)- üldpopulatsioonist valitud objektide kogum. Variatsiooniseeria- statistiline jaotus, mis koosneb variantidest (juhusliku suuruse väärtused) ja nende vastavatest sagedustest. Näide: x- juhusliku suuruse väärtus (10-aastaste tüdrukute mass); m- esinemissagedus. Mood– juhusliku suuruse väärtus, mis vastab suurimale esinemissagedusele. (Ülaltoodud näites on moe jaoks kõige levinum väärtus 24 kg: m = 20). Mediaan- juhusliku suuruse väärtus, mis jagab jaotuse pooleks: pooled väärtustest asuvad mediaanist paremal, pooled (mitte enam) - vasakul. Näide: 1, 1, 1, 1, 1. 1, 2, 2, 2, 3
, 3, 4, 4, 5, 5, 5, 5, 6, 6, 7
, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8
, 8, 9, 9, 9, 10, 10, 10, 10, 10, 10 Näites vaatleme juhusliku muutuja 40 väärtust. Kõik väärtused on järjestatud kasvavas järjekorras, võttes arvesse nende esinemise sagedust. On näha, et 20 (pool) 40 väärtusest asuvad valitud väärtusest 7 paremal. Nii et 7 on mediaan. Hajuvuse iseloomustamiseks leiame väärtused, mis ei olnud kõrgemad kui 25 ja 75% mõõtmistulemustest. Neid väärtusi nimetatakse 25. ja 75 protsentiilid
. Kui mediaan poolitab jaotuse, lõigatakse 25. ja 75. protsentiil sellest veerandi võrra ära. (Mediaani ennast, muide, võib pidada 50. protsentiiliks.) Nagu näitest näha, on 25. ja 75. protsentiil vastavalt 3 ja 8. kasutada diskreetne
(punkt) statistiline jaotus ja pidev
(intervall) statistiline jaotus. Selguse huvides on statistilised jaotused vormil graafiliselt kujutatud sageduse hulknurk
või - histogrammid
. Sageduse hulknurk- katkendjoon, mille lõigud ühendavad punkte koordinaatidega ( x 1, m 1), (x2,m2), ... või jaoks suhteliste sageduste hulknurk
- koordinaatidega ( x 1, p * 1), (x 2, p * 2), ...(joonis 1). Joon.1 Joon.2 Sageduse histogramm- ühele sirgele ehitatud kõrvuti asetsevate ristkülikute kogum (joon. 2), ristkülikute alused on ühesugused ja võrdsed dx
, ja kõrgused on võrdsed sageduse suhtega dx
, või R*
To dx
(tõenäosuse tihedus). Näide: Sageduse hulknurk Nimetatakse suhtelise sageduse ja intervalli laiuse suhet tõenäosustihedus f(x)=m i / n dx = p* i / dx
Näide histogrammi koostamisest . Kasutame eelmise näite andmeid. 1. Klassivahede arvu arvutamine Kus n
- vaatluste arv. Meie puhul n = 100
. Seega: 2. Intervalli laiuse arvutamine dx
: 3. Intervallide seeria koostamine: tulpdiagramm


 - esimese tulemuste rea jaoks.
- esimese tulemuste rea jaoks. - teise tulemuste rea jaoks.
- teise tulemuste rea jaoks. - esimese rea jaoks.
- esimese rea jaoks. - teise rea jaoks.
- teise rea jaoks. - esimese rea jaoks.
- esimese rea jaoks. - teise rea jaoks.
- teise rea jaoks.





 Ja
Ja 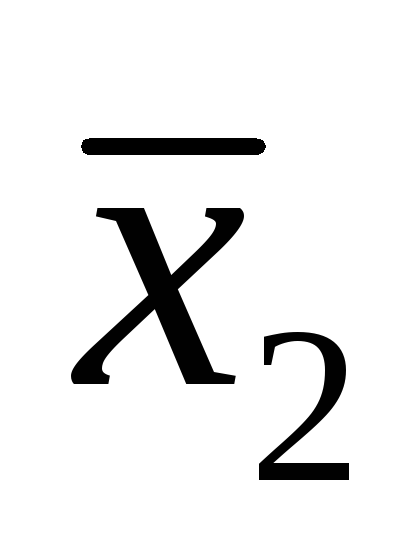 oluline ja valim ei kuulu samasse üldkogumisse. Kui t exp<
t крит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n 1 +n 2
результатов.
oluline ja valim ei kuulu samasse üldkogumisse. Kui t exp<
t крит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n 1 +n 2
результатов.
![]()
Uuringu korraldus
3.1.1 Matemaatilise statistika ülesanded ja meetodid
3.1.2 Proovitüübid
 näidis.
näidis. ,
,
 .
. :
: .
.
 .
.




 .
. . (3.2)
. (3.2)
–1
–1
x x 1 x2 x 3 x4 ...
x n
lk lk 1 lk 2 lk 3 lk 4 ...
p n
x x 1 x2 x 3 x4 ...
x n
m m 1 m2 m 3 m4 ...
m n


X, kg
m

 m m i /n f(x)
m m i /n f(x)x, kg 2,7
2,8
2,9
3,0
3,1
3,2
3,3
3,4
3,5
3,6
3,7
3,8
3,9
4,0
4,1
4,2
4,3
4,4
m

![]()
 ,
, 
dx 2.7-2.9
2.9-3.1
3.1-3.3
3.3-3.5
3.5-3.7
3.7-3.9
3.9-4.1
4.1-4.3
4.3-4.5
m
f(x) 0.3
0.75
1.25
0.85
0.55
0.6
0.4
0.25
0.05