
Fontolja meg néhányat fogalmakés főbb megközelítései osztályozás hibákat. A számítási módszer szerint a hibákat abszolút és relatívra oszthatjuk.
Abszolút hiba egyenlő a mennyiség átlagos mérésének különbségével xés ennek a mennyiségnek a valódi értéke:
Bizonyos esetekben, ha szükséges, számítsa ki az egyszeri meghatározások hibáit:

Vegye figyelembe, hogy a kémiai elemzésben mért érték lehet a komponens tartalma és az analitikai jel is. Attól függően, hogy az elemzés eredménye túl- vagy alábecsüli-e a hibát, a hibák lehetnek pozitívÉs negatív.
Relatív hiba törtekben vagy százalékokban fejezhető ki, és általában nincs előjele:
 vagy
vagy 
Lehetőség van a hibák osztályozására eredetük szerint. Mivel rendkívül sok hibaforrás létezik, ezek besorolása nem lehet egyértelmű.
Leggyakrabban a hibákat az azokat okozó okok jellege szerint osztályozzák. Ebben az esetben a hibák el vannak osztva szisztematikusanég és hétköznapi, kihagyások (vagy durva hibák) is megkülönböztethetők.
NAK NEK szisztematikus olyan hibákat tartalmazzon, amelyek tartós ok okozta, minden mérésben állandó, vagy állandó törvény szerint változik, azonosítható és kiküszöbölhető.
Véletlen Az ismeretlen okok miatti hibák matematikai statisztikai módszerekkel becsülhetők.
hiányzik - ez egy olyan hiba, amely élesen torzítja az elemzés eredményét, és általában könnyen észlelhető, amelyet általában az elemző hanyagsága vagy hozzá nem értése okoz. ábrán. Az 1.1 egy diagram, amely elmagyarázza a szisztematikus és a hibák és hiányosságok fogalmát. Egyenes 1 megfelel annak az ideális esetnek, amikor nincsenek szisztematikus és véletlenszerű hibák az összes N definícióban. A 2. és 3. sor a kémiai elemzés idealizált példája is. Egy esetben (2. egyenes) a véletlenszerű hibák teljesen hiányoznak, de mindegyik N a definícióknak állandó negatív szisztematikus hibájuk van Δх; egyébként (sor 3) nincs szisztematikus hiba. A vonal a valós helyzetet tükrözi 4: Véletlenszerű és szisztematikus hibák egyaránt előfordulnak.

Rizs. 4.2.1 A kémiai elemzés szisztematikus és véletlenszerű hibái.
A hibák szisztematikusra és véletlenre való felosztása bizonyos mértékig feltételes.
Az eredmények egy mintájának szisztematikus hibái, ha nagyobb számú adatot veszünk figyelembe, véletlenszerűvé válhatnak. Például véletlenszerűvé válik az eszköz helytelen leolvasásából adódó szisztematikus hiba, amikor különböző laboratóriumokban különböző eszközökön analitikai jelet mérünk.
Reprodukálhatóság jellemzi az egyes definíciók egymáshoz való közelségének fokát, az egyes eredmények átlaghoz viszonyított szórását (1.2. ábra).

Rizs. 4.2..2. A kémiai elemzés reprodukálhatósága és pontossága
Egyes esetekben a "reprodukálhatóság" kifejezéssel együtt használja a kifejezést "konvergencia". Ugyanakkor a konvergencia alatt a párhuzamos meghatározások eredményeinek szórását, a reprodukálhatóságon pedig a különböző módszerekkel, különböző laboratóriumokban, különböző időpontokban stb. kapott eredmények szórását értjük.
Jobb a kémiai elemzés minősége, amely a szisztematikus hiba nullához való közelségét tükrözi. A helyesség a kapott elemzési eredménynek a mért érték valós értékétől való eltérését jellemzi (lásd 1.2. ábra).
Népesség - az összes elképzelhető eredmény hipotetikus halmaza -∞-től +∞-ig;
A kísérleti adatok elemzése azt mutatja, hogy nagy hibák figyelhetők meg ritkábban mint a kicsik. Azt is meg kell jegyezni, hogy a megfigyelések számának növekedésével ugyanazok a különböző előjelű hibák fordulnak elő. egyaránt gyakran. A véletlenszerű hibák ezen és egyéb tulajdonságait normál eloszlás ill Gauss egyenlet, amely a valószínűségi sűrűséget írja le  .
.


Ahol x- egy valószínűségi változó értéke;
μ – Általános átlag (várható érték- állandó paraméter);
Várható érték-
folytonos valószínűségi változó esetén az a határ, amelyre az átlag hajlik  a minta korlátlan növekedésével. Így a matematikai elvárás a teljes népesség egészére vonatkozó átlagérték, néha ún
Általános átlag.
a minta korlátlan növekedésével. Így a matematikai elvárás a teljes népesség egészére vonatkozó átlagérték, néha ún
Általános átlag.
σ 2 - diszperzió (állandó paraméter) - jellemzi egy valószínűségi változó matematikai elvárásaihoz viszonyított szóródását;
σ a szórás.
Diszperzió- jellemzi egy valószínűségi változó szóródását a matematikai elvárása alapján.
Mintapopuláció (minta)- a kutató által birtokolt eredmények valós száma (n), n = 3 ÷ 10.
Normál elosztási törvény elfogadhatatlan a mintapopuláció kisszámú változásának (általában 3-10) kezeléséhez – még akkor is, ha a sokaság egésze normális eloszlású. Kis minták esetén normál eloszlás helyett használja Diák elosztás (t- terjesztés), amely összekapcsolja a mintapopuláció három fő jellemzőjét -
A konfidencia intervallum szélessége;
A megfelelő valószínűség;
Minta nagysága.
Az adatok matematikai statisztikai módszerekkel történő feldolgozása előtt azonosítani kell hiányzik(durva hibák), és kizárja azokat a vizsgált eredmények közül. Az egyik legegyszerűbb a hiányosságok észlelésének módszere Q segítségével - egy kritérium az n mérések számával< 10:

Ahol R = x Max - X min– variációs tartomány; x 1 - gyanúsan kiemelkedő érték; x 2 - egyetlen meghatározás eredménye, értékében legközelebb ehhez x 1 .
A kapott értéket összehasonlítjuk a Q crit kritikus értékkel P = 0,95 konfidenciaszinten. Ha Q > Q crit, akkor a kiesési eredmény hiányos, és eldobásra kerül.
A minta főbb jellemzői. Mintavételhez innen n
eredményeket számítanak ki átlagos, :
:

És diszperzió, amely az eredmények szórását jellemzi az átlaghoz képest:

Az explicit formában megjelenő diszperzió nem használható az eredmények szórásának számszerűsítésére, mivel a dimenziója nem egyezik az elemzési eredmény dimenziójával. A szóródás jellemzésére használja szórás,S.

Ezt az értéket standard (vagy standard) eltérésnek vagy egyetlen eredmény standard hibájának is nevezik.
RÓL RŐLrelatív szórás vagy az összefüggésből számítjuk ki a variációs együtthatót (V).

A számtani átlag szórása kiszámítja:

és az átlag szórása

Meg kell jegyezni, hogy minden érték - diszperzió, szórás és relatív szórás, valamint az aritmetikai átlag szórása és a számtani átlag szórása - jellemzi a kémiai elemzés eredményeinek reprodukálhatóságát.
Kisebb (n<20) выборок из нормально распределенной генеральной совокупности t – распределение (т.е. распределение нормированной случайной величины) характеризуется соотношением

Aholt p , f – Student eloszlása a szabadságfokok számával f= n-1 és a bizalom szintje P=0,95(vagy szignifikancia szint p=0,05).
A t - eloszlások értékeit a táblázatokban adjuk meg, egy mintára számítjuk ki n eredmények, a mért mennyiség konfidenciaintervallumának értéke adott megbízhatósági valószínűség mellett a képlet szerint

Megbízhatósági intervallum jellemzi mind a kémiai analízis eredményeinek reprodukálhatóságát, mind - ha ismert az x ist valós értéke - azok helyességét.
Példa a 2. számú ellenőrzési munka elvégzésére
Gyakorlat
Nál nél A levegő elemzése a nitrogéntartalomra kromatográfiás módszerrel két kísérletsorozatban, a következő eredményeket kaptuk:
Megoldás:
A Q-kritérium segítségével ellenőrizzük a sorozatban a durva hibák jelenlétét. Miért rendezzük az eredményeket csökkenő sorrendbe (minimálistól maximumig vagy fordítva):
Első epizód:
77,90<77,92<77,95<77,99<78,05<78,07<78,08<78,10
Ellenőrizzük a sorozat extrém eredményeit (van-e durva hiba).
A kapott értéket összehasonlítjuk a táblázatos értékkel (a pályázat 2. táblázata). n=8 esetén p=0,95 Q tab=0,55.
Mert Q tabulátor >Q 1 számítás, a bal szélső számjegy nem "kihagyás".
A jobb szélső számjegy ellenőrzése

Qcalc A jobb szélső ábra szintén nem hibás. Nekünk van a második sor eredményei igen, növekvő sorrendben: 78,02<78,08<78,13<78,14<78,16<78,20<78,23<78,26. Ellenőrizzük a kísérletek szélsőséges eredményeit - hogy tévesek-e. Q(n=8, p=0,95)=0,55. Táblázat értéke. A bal szélső érték nem hiba. A jobb szélső számjegy (rossz-e). Azok. 0,125<0,55 A jobb szélső szám nem „kihagyás”. A kísérletek eredményeit statisztikai feldolgozásnak vetjük alá. Kiszámoljuk az eredmények súlyozott átlagát: Az átlaghoz viszonyított diszperzió: Szórás: A számtani átlag szórása: Kicsiknek (n<20)
выборках из нормально распределенной
генеральной совокупности следует
использовать t
– распределение, т.е. распределение
Стьюдента при числе степени свободы
f=n-1
и доверительной вероятности p=0,95. A t - eloszlás táblázatai segítségével határozza meg egy n - eredményű mintára a mért érték konfidenciaintervallumának értékét egy adott konfidenciaszinthez. Ez az intervallum kiszámítható: VAL VEL kiegyenlíteni az eltéréseketÉs átlagos eredmények két mintakészlet. Két variancia összehasonlítása az F-eloszlás (Fisher-eloszlás) segítségével történik. Ha két mintapopulációnk van S 2 1 és S 2 2 szórással és f 1 =n 1 -1, illetve f 2 =n 2 -1 szabadsági fokokkal, akkor kiszámítjuk F értékét: F=S 2 1 / S 2 2 És a számláló mindig a nagyobb a kettő közülösszehasonlította a minta eltéréseit. A kapott eredményt összehasonlítjuk a táblázat értékével. Ha F 0 > F crit (p=0,95-nél; n 1, n 2), akkor a szórások közötti eltérés szignifikáns, és a vizsgált minták reprodukálhatóságában különböznek. Ha a szórások közötti eltérés nem szignifikáns, akkor össze lehet hasonlítani a két mintahalmaz x 1 és x 2 átlagát, azaz. derítse ki, hogy van-e statisztikailag szignifikáns különbség a teszteredmények között. A probléma megoldásához használja a t - disztribúciót. Számítsa ki előre két diszperzió súlyozott átlagát: És a súlyozott átlagos szórás majd t értéke: Jelentése t expösszehasonlít t Kréta a szabadsági fokok számával f=f 1 +f 2 =(n 1 +n 2 -2) és a minta konfidenciaszintjével p=0,95. Ha ugyanakkor t exp
>
t Kréta, akkor az átlag közötti különbség 2. számú ellenőrzési feladat Az X komponens tartalmának levegőanalízise kromatográfiás módszerrel két sorozat esetében a következő eredményeket adta (1. táblázat). 3. Mindkét minta eredménye ugyanahhoz az általános sokasághoz tartozik-e? Teszt Student-féle t-próbával (p = 0,95; n = 8). táblázat-4.2.1- Kiinduló adatok a 2. számú ellenőrzési feladathoz opció számát Összetevő A matematikai statisztika módszereit általában a kutatási anyagok elemzésének minden szakaszában használják, hogy kiválasszák a konkrét mintaadatokon a problémák megoldásának stratégiáját, értékelve a kapott eredményeket. Az anyag feldolgozásához matematikai statisztikai módszereket alkalmaztunk. Az anyagok matematikai feldolgozása lehetővé teszi az objektív információk mennyiségi paramétereinek egyértelmű azonosítását, értékelését, elemzését és bemutatását különböző arányokban és függőségekben. Lehetővé teszik az összegyűjtött anyagokban a mennyiségi információkat tartalmazó, egy bizonyos esethalmazra vonatkozó mennyiségi információkat tartalmazó értékek változásának mértékét, amelyek egy része megerősíti az állítólagos összefüggéseket, mások pedig nem tárják fel azokat, kiszámítják a kiválasztott esetcsoportok közötti mennyiségi különbségek megbízhatóságát, és megkapják a tények helyes értelmezéséhez szükséges egyéb matematikai jellemzőket. A vizsgálat során kapott különbségek szignifikanciáját Student-féle t-próbával határoztuk meg. A következő értékeket számoltuk ki. 1. A minta számtani átlaga. A vizsgált populáció átlagos értékét jellemzi. Jelöljük a mérési eredményeket. Akkor: ahol Y az összes érték összege, amikor az aktuális i index 1-ről n-re változik. 2. Szórás (szórás), amely a szóban forgó sokaság szórását, szórását jellemzi a számtani átlaghoz képest. = (x max - x min)/k hol van a szórás хmax - a táblázat maximális értéke; xmin - a táblázat minimális értéke; k - együttható 3. A számtani átlag standard hibája vagy a reprezentativitási hiba (m). A számtani átlag standard hibája a minta számtani átlagának az általános sokaság számtani átlagától való eltérésének mértékét jellemzi. A számtani átlag standard hibáját a következő képlettel számítjuk ki: ahol y a mérési eredmények szórása, n - mintanagyság. Minél kisebb m, annál nagyobb az eredmények stabilitása, stabilitása. 4. Hallgatói kritérium. (a számlálóban - a két csoport átlagának különbsége, a nevezőben - ezen átlagok standard hibáinak négyzetösszegének négyzetgyöke). A kapott vizsgálati eredmények feldolgozásakor Excel csomaggal ellátott számítógépes programot használtunk. A vizsgálatot mi végeztük az általánosan elfogadott szabályok szerint, és 3 szakaszban zajlott. Első lépésben a vizsgált kutatási problémáról beérkezett anyagot összegyűjtöttük és elemeztük. Kialakult a tudományos kutatás tárgya. Az irodalom elemzése ebben a szakaszban lehetővé tette a vizsgálat céljának és célkitűzéseinek pontosítását. Megtörtént a 30 méteres futástechnika elsődleges tesztelése.<... class="gads_sm"> A harmadik szakaszban a tudományos kutatás eredményeként nyert anyagok rendszerezése, a kutatási problémával kapcsolatos összes rendelkezésre álló információ összegzése megtörtént. A kísérleti vizsgálatot a "Lyakhovichi Középiskola" Állami Oktatási Intézmény alapján végezték, összesen 20 6. osztályos (11-12 éves) tanulóból állt a minta. 3. fejezet A vizsgálat eredményeinek elemzése A pedagógiai kísérlet eredményeként a kontroll és a kísérleti csoport tanulói körében azonosítottuk a 30 méteres futástechnika kezdeti szintjét (1-2. melléklet). A kapott eredmények statisztikai feldolgozása lehetővé tette a következő adatok megszerzését (6. táblázat). 6. táblázat A futási minőség kezdeti szintje A 6. táblázatból látható, hogy a kontroll és a kísérleti csoport sportolóinak átlagos pontszáma statisztikailag nem tér el egymástól, a kísérleti csoportban 3,6, a kontrollcsoportban 3,7 pont volt az átlagpontszám. T-teszt mindkét csoportban temp=0,3; Р?0,05, tcrit=2,1-nél; A kezdeti tesztelés eredményei azt mutatták, hogy a mutatók nem függenek a képzéstől, és véletlenszerűek. A kezdeti tesztelés szerint a kontrollcsoport futásminőségi mutatói kismértékben meghaladták a kísérleti csoportét. A csoportok között azonban nem volt statisztikailag szignifikáns különbség, ami a kontroll és a kísérleti csoport tanulóinak azonosságát bizonyítja a 30 méteres futás technikájában. A kísérlet során mindkét csoportban javultak a futástechnika eredményességét jellemző mutatók. Ez a javulás azonban a kísérletben résztvevők különböző csoportjaiban eltérő jellegű volt. A tréning eredményeként a kontrollcsoportban rendszeres enyhe mutatók emelkedés (3,8 pont) derült ki. A 2. mellékletből látható, hogy a kísérleti csoportban a mutatók nagymértékű növekedését mutatták ki. A tanulók az általunk javasolt program szerint tanultak, ami jelentősen javította teljesítményüket. 7. táblázat. A futás minőségének változása a kísérleti csoport alanyaiban A kísérlet során azt találtuk, hogy a kísérleti csoportban a megnövekedett terhelések szignifikáns javulást eredményeztek a sebesség fejlődésében, mint a kontrollcsoportban. Serdülőkorban célszerű a gyorsaságot a mozgásgyakoriság növelését célzó testnevelési eszközök túlnyomó alkalmazásával fejleszteni. 12-15 éves korban a gyorsasági képességek megnövekednek, elsősorban a gyorsasági-erő- és erőgyakorlatok alkalmazásának eredményeként, amelyeket a kosárlabda és atlétika sportszakaszában testnevelési órák és tanórán kívüli foglalkozások lebonyolítása során alkalmaztunk. A kísérleti csoportban végzett órák során a szövődmények és a motoros tapasztalatok szigorú fokozatos felosztását végezték el. A hibákat időben kijavították. Amint azt a tényleges adatok elemzése kimutatta, a kísérleti oktatási módszertan a futástechnika minőségében jelentős változást hozott (hőmérséklet=2,4). A kísérleti csoportban elért eredmények elemzése és a kontroll csoportban kapott adatokkal való összehasonlítása az általánosan elfogadott tanítási módszerekkel alapot ad annak állítására, hogy az általunk javasolt módszer növeli az oktatás hatékonyságát. Így az iskolai 30 méteres futás módszertanának fejlesztése szakaszában feltártuk a tesztelési mutatók változásának dinamikáját a kísérleti és a kontrollcsoportban. A kísérlet után a vételi teljesítmény minősége a kísérleti csoportban 4,9 pontra emelkedett (t=3,3; P?0,05). A kísérlet végére a futástechnika minősége a kísérleti csoportban magasabb volt, mint a kontrollcsoportban. Matematikai statisztika a matematikának egy olyan ága, amely a statisztikai megfigyelési adatok tudományos és gyakorlati célú gyűjtésének, elemzésének és feldolgozásának módszereivel foglalkozik. A matematikai statisztika módszereit azokban az esetekben alkalmazzák, amikor az eloszlást vizsgálják tömegjelenségek, azaz tárgyak vagy jelenségek nagy gyűjteménye terjesztett bizonyos alapon. Tanulmányozzuk a homogén objektumok halmazát, amelyeket minőségi vagy mennyiségi jellegű közös jellemző vagy tulajdonság egyesít. Egy ilyen halmaz egyes elemeit tagjainak nevezzük. Egy populáció teljes létszáma annak hangerő. A rendszer meghívja az összes objektum halmazát, amelyet valamilyen attribútum egyesít Általános népesség. A gyártott termékek minőségi értékelése során vizsgálják például a lakosság jövedelmét, a részvények piaci értékét vagy az állami szabványtól való eltérést. A matematikai statisztika szorosan kapcsolódik a valószínűségelmélethez, és annak következtetéseire támaszkodik. Különösen a koncepció népesség a matematikai statisztikában megfelel a fogalomnak elemi események tere a valószínűségelméletben. A teljes általános populáció vizsgálata legtöbbször lehetetlen vagy nem praktikus a jelentős anyagi költségek, a vizsgálat tárgyának sérülése vagy megsemmisülése miatt. Így nem lehet objektív és teljes körű információt szerezni az egész régió lakosságának jövedelméről; minden egyes lakos. A kutatási objektum leromlása miatt lehetetlen megbízható információt szerezni például egyes gyógyszerek vagy élelmiszerek minőségéről. Fő feladat a matematikai statisztika az általános sokaság vizsgálata mintaadatok alapján, a céltól függően, vagyis a sokaság valószínűségi tulajdonságainak vizsgálata: az eloszlás törvénye, a numerikus jellemzők stb. vezetői döntések meghozatalára a bizonytalanság körülményei között. A matematikai statisztika egyik módszere az mintavételi módszer. A gyakorlatban leggyakrabban nem a teljes sokaságot vizsgálják, hanem egy korlátozott mintát. minta(mintakészlet) véletlenszerűen kiválasztott objektumok halmaza. A mintavételi módszer segítségével nem a teljes sokaságot, hanem a mintát ( x 1 ,x 2 ,...,x n) korlátozott számú megfigyelés eredményeként. Ezután ennek a mintának a valószínűségi tulajdonságai alapján ítéletet hozunk egy bizonyos általános sokaságból a teljes sokaságról. A mintavételhez különféle mintavételi módszereket alkalmaznak. A vizsgálat tárgyai a vizsgálat után az általános populációban lehetnek, ami megfelel A mintát ún reprezentatív vagy reprezentatív,
ha jól reprodukálja az általános sokaságot, vagyis a minta valószínűségi tulajdonságai egybeesnek vagy közel állnak magának az általános sokaságnak a tulajdonságaihoz. Tehát a mintavételi módszer alkalmazásának hatékonysága számos feltétel mellett nő, beleértve a következőket: A vizsgált mintaelemek száma elég a következtetések levonásához, azaz a minta reprezentatív vagy " reprezentatív». Tehát egy tételben megfelelő számú alkatrészt, amelynek minőségét ellenőrizzük (házasság), a valószínűségszámítás és a matematikai statisztika törvényei alapján állapítják meg. Mintaelemek kell változatos, véletlenszerűen vett, azok. elvét tiszteletben kell tartani randomizálás. Tanult tulajdonság –
tipikus, jellemző a vizsgált objektumok halmazának minden elemére –
azok. az egész lakosság számára. A vizsgált tulajdonság az jelentős ennek az osztálynak az összes elemére. A statisztikai sokaság mintavételi módszerrel vizsgált előjelének változását ún variáció, és a jellemző megfigyelt értékei x én
-
választási lehetőség. Abszolút frekvencia
(frekvencia vagy frekvencia) lehetőségek x én az értékkel rendelkező sokaság (általános vagy minta) tagjainak száma x én(azaz ez a részecskék száma én-
osztály). A változat rangsorolt csoportosítása az attribútum egyedi értékei (vagy a változási intervallumok) szerint, pl. növekvő sorrendbe rendezett opciók sorozatát hívják variációs sorozat. Bármely függvény ( x 1 ,x 2 ,…,x n) a megfigyelések eredményeiből x 1 ,x 2 ,…,x n a vizsgált valószínűségi változót ún statisztika. Az általános népesség elfogadott mennyisége
kijelöl N,
abszolút frekvenciái az N én, minta nagysága - n,
abszolút frekvenciái az n én. Ez nyilvánvaló A gyakoriság és a népességszám arányát ún relatív gyakoriság vagy statisztikai valószínűségés jelöltük W én
vagy Ha az opciók száma nagy vagy közel van a minta méretéhez (diszkrét eloszlással), valamint ha a minta egy folytonos általános sokaságból készül, akkor a variációs sorozatot nem egyedenként állítják össze - pont -értékeket, de időközönként populációs értékek. A táblázat által reprezentált, csoportosítási eljárással felépített variációs sorozatokat hívjuk meg intervallum. Intervallumvariációs sorozat összeállításakor a táblázat első sora a vizsgált populáció egyenlő hosszúságú értékeinek intervallumokkal van kitöltve, a második a megfelelő abszolút vagy relatív gyakorisággal. Legyen ennek eredményeként néhány általános populációból n megfigyelések letöltött térfogatminta P.
Statisztikai eloszlás
minták opciók listájának és a hozzájuk tartozó abszolút vagy relatív gyakoriságuknak nevezzük. Pont variációs sorozat abszolút
frekvenciák táblázattal ábrázolható: x én x k n én n k és Pont variációs sorozat relatív gyakoriságok táblázattal ábrázolva: x én x k és Az intervallumeloszlás felépítésénél szabályok vonatkoznak az intervallumok számának vagy az egyes intervallumok méretének megválasztására. Itt az optimális arány a kritérium: az intervallumok számának növekedésével javul a reprezentativitás, de nő az adatok mennyisége és a feldolgozási idő. Különbség x max
-
x min a legnagyobb és legkisebb érték között van egy változat, az ún nagy léptékben minták. Az intervallumok számának megszámlálásához kÁltalában Sturgess empirikus képletét használják: k= 1+3,3221g n (3.1) (a legközelebbi egész számra kerekítést feltételezve). Ennek megfelelően az egyes intervallumok értéke h képlettel lehet kiszámítani: x min = x max -
0,5h. Minden intervallumnak legalább öt opciót kell tartalmaznia. Abban az esetben, ha az intervallumban az opciók száma kevesebb, mint öt, akkor a szomszédos intervallumokat szokás kombinálni. * Ez a munka nem tudományos munka, nem végleges minősítő munka, és az összegyűjtött információk feldolgozásának, strukturálásának és formázásának eredménye, amelyet az oktatási munka önálló előkészítéséhez kívánnak felhasználni. Bevezetés. Hivatkozások. A matematikai statisztika módszerei Bevezetés. A matematikai statisztika alapfogalmai. A pszichológiai és pedagógiai kutatások eredményeinek statisztikai feldolgozása. Hivatkozások. A matematikai statisztika módszerei Bevezetés. A matematikai statisztika alapfogalmai. A pszichológiai és pedagógiai kutatások eredményeinek statisztikai feldolgozása. Hivatkozások. Bevezetés. A matematika más tudományokra való alkalmazásának csak egy adott jelenség mély elméletével együtt van értelme. Ezt fontos szem előtt tartani, hogy ne tévedjünk bele egy egyszerű képletjátékba, ami mögött nincs valódi tartalom. akadémikus Yu.A. Nagyvárosi A pszichológiai és pedagógiai elméleti kutatási módszerek lehetővé teszik a vizsgált jelenségek minőségi jellemzőinek feltárását. Ezek a jellemzők teljesebbek és mélyebbek lesznek, ha a felhalmozott empirikus anyagot kvantitatív feldolgozásnak vetjük alá. A pszichológiai és pedagógiai kutatások keretében végzett kvantitatív mérések problémája azonban igen összetett. Ez a komplexitás elsősorban a pedagógiai tevékenység és eredményeinek szubjektív-okozati sokszínűségében rejlik, éppen a mérés tárgyában, amely a folyamatos mozgás és változás állapotában van. Ugyanakkor a mennyiségi mutatók bevezetése a tanulmányba ma szükséges és kötelező eleme a pedagógiai munka eredményeiről szóló objektív adatok megszerzésének. Ezek az adatok általában a pedagógiai folyamat különböző összetevőinek közvetlen vagy közvetett mérésével, valamint a megfelelően felépített matematikai modell releváns paramétereinek számszerűsítésével nyerhetők. Ebből a célból a pszichológiai és pedagógiai problémák tanulmányozása során a matematikai statisztika módszereit alkalmazzák. Segítségükkel különféle feladatokat oldanak meg: tényanyag feldolgozása, új, kiegészítő adatok beszerzése, a vizsgálat tudományos megszervezésének megalapozása és egyebek. 2. A matematikai statisztika alapfogalmai Számos pszichológiai és pedagógiai jelenség elemzésében kiemelkedően fontos szerepet töltenek be az átlagértékek, amelyek egy minőségileg homogén populáció általánosított jellemzői egy bizonyos mennyiségi jellemző szerint. Lehetetlen például kiszámítani az egyetemi hallgatók átlagos szakterületét vagy nemzetiségét, mivel ezek minőségileg heterogén jelenségek. Másrészt meg lehet és szükséges átlagosan meghatározni tanulmányi teljesítményük számszerű jellemzőjét (átlagpontszám), módszertani rendszerek és technikák hatékonyságát stb. A pszichológiai és pedagógiai kutatásokban általában különböző típusú átlagokat használnak: számtani átlag, geometriai átlag, medián, módus és mások. A leggyakoribb a számtani átlag, a medián és a módusz. A számtani átlagot olyan esetekben alkalmazzuk, amikor a meghatározó tulajdonság és e jellemző között egyenes arányos kapcsolat áll fenn (például, ha a vizsgált csoport teljesítménye javul, minden tagjának teljesítménye javul). A számtani átlag az értékek összegének a számukkal való elosztásának hányadosa, és a következő képlettel számítjuk ki: ahol X a számtani átlag; X1, X2, X3 ... Xn - az egyéni megfigyelések eredményei (technikák, akciók), n - a megfigyelések száma (módszerek, intézkedések), Az összes megfigyelés (technika, akció) eredményének összege. A medián (Me) az átlagos pozíció mérőszáma, amely egy jellemző értékét jellemzi egy rendezett (növekedés vagy csökkenés alapján épített) skálán, amely a vizsgált sokaság közepének felel meg. A medián az ordinális és mennyiségi jellemzőkre határozható meg. Ennek az értéknek a helyét a következő képlet határozza meg: Medián hely = (n + 1) / 2 Például. A vizsgálat eredményei alapján megállapították, hogy: – „kiváló” tanulók – a kísérletben résztvevők közül 5 fő; – 18 fő tanul „jól”; - "kielégítőnek" - 22 fő; - "nem kielégítőnek" - 6 fő. Mivel összesen N = 54 fő vett részt a kísérletben, a minta közepe egyenlő a fővel. Ebből az a következtetés vonható le, hogy a hallgatók több mint fele a „jó” osztályzat alatt tanul, vagyis a medián több mint „kielégítő”, de kevesebb, mint „jó” (lásd az ábrát). A Mode (Mo) a leggyakoribb jellemző érték a többi érték között. A legmagasabb frekvenciájú osztálynak felel meg. Ezt az osztályt modális értéknek nevezzük. Például. Ha a kérdőív kérdése: „jelölje meg az idegennyelv-tudás fokát”, akkor a válaszok kiosztásra kerültek: 1 - folyékonyan - 25 2 – eleget tudok a kommunikációhoz – 54 3 - Tudom, de kommunikációs nehézségeim vannak - 253 4 – nehezen értem – 173 5 - nem tudom - 28 Nyilvánvalóan itt a legjellemzőbb jelentés: „Tudom, de nehezen kommunikálok”, ami modális lesz. Tehát a mód -253. A matematikai módszerek alkalmazása során a pszichológiai és pedagógiai kutatásokban nagy jelentőséget tulajdonítanak a variancia és a négyzetes (szórás) számításának. A variancia egyenlő az opciók értékének az átlagtól való eltéréseinek négyzetes átlagával. Ez a vizsgált változó értékeinek (például tanulói osztályzatok) átlagérték körüli szóródásának egyéni eredményeinek egyik jellemzője. A diszperzió kiszámítása a következők meghatározásával történik: eltérések az átlagértéktől; a megadott eltérés négyzete; az eltérés négyzeteinek összege és az eltérés négyzetének átlagértéke (lásd 6.1. táblázat). A diszperziós értéket különféle statisztikai számításokban használják, de közvetlenül nem figyelhetők meg. A megfigyelt változó tartalmához közvetlenül kapcsolódó mennyiség a szórás. 6.1. táblázat Varianciaszámítási példa Jelentése indikátor Eltérés az átlagtól eltérések 2
– 3 = – 1 A szórás megerősíti a számtani átlag tipikusságát és indikatív jellegét, tükrözi az előjelek számértékei ingadozásának mértékét, amelyből az átlagérték származik. Ez egyenlő a diszperzió négyzetgyökével, és a képlet határozza meg: ahol: - négyzetgyök. Kis számú megfigyelés (művelet) esetén - kevesebb, mint 100 - a képlet értékében nem "N", hanem "N - 1"-et kell tenni. A számtani átlag és az átlagos négyzet a vizsgálat során kapott eredmények fő jellemzői. Lehetővé teszik az adatok összegzését, összehasonlítását, az egyik pszichológiai és pedagógiai rendszer (program) előnyeinek megállapítását a másikkal szemben. A négyzetes (standard) eltérést széles körben használják a diszperzió mértékeként különböző jellemzők esetében. A vizsgálat eredményeinek értékelésekor fontos meghatározni egy valószínűségi változó szóródását az átlagérték körül. Ezt a diszperziót a Gauss-törvény (egy valószínűségi változó valószínűségének normális eloszlásának törvénye) segítségével írjuk le. A törvény lényege, hogy egy adott attribútum mérése során egy adott elemhalmazban számos ellenőrizhetetlen ok miatt mindig mindkét irányban vannak eltérések a normától, és minél nagyobbak az eltérések, annál ritkábban fordulnak elő. Az adatok további feldolgozása során kiderülhet: variációs együttható (stabilitás) a vizsgált jelenség, amely a szórás százalékos aránya a számtani átlaghoz képest; a ferdeség mértéke, amely megmutatja, hogy a túlnyomó számú eltérés melyik irányba irányul; a hidegség mértéke, amely egy valószínűségi változó értékeinek az átlag körüli felhalmozódásának mértékét mutatja, stb. Mindezek a statisztikák segítenek a vizsgált jelenségek jeleinek pontosabb azonosításában. A változók közötti asszociációs mérőszámok. A statisztikákban két vagy több változó közötti kapcsolatokat (függőségeket) nevezzük korreláció. A becslés a korrelációs együttható értékével történik, amely a kapcsolat mértékének és nagyságának mértéke. Sok korrelációs együttható létezik. Ezeknek csak egy részét tekintsük, amely figyelembe veszi a változók közötti lineáris kapcsolat meglétét. Választásuk a változók mérésére szolgáló skáláktól függ, amelyek közötti kapcsolatot fel kell mérni. A Pearson és Spearman együtthatók leggyakrabban a pszichológiában és a pedagógiában használatosak. Fontolja meg a korrelációs együtthatók értékének kiszámítását konkrét példákon. 1. példa: Mérjünk két összehasonlított X (családi állapot) és Y (egyetemi kizárás) változót egy dichotóm skálán (a címskála speciális esete). Az összefüggés meghatározásához a Pearson-együtthatót használjuk. Azokban az esetekben, amikor nincs szükség az X és Y változók különböző értékeinek előfordulási gyakoriságának kiszámítására, célszerű a korrelációs együtthatót egy kontingenciatáblázat segítségével kiszámítani (lásd a 6.2, 6.3, 6.4 táblázatokat), amely megmutatja két változó (jellemzők) értékpárjainak együttes előfordulásának számát. A - azon esetek száma, amikor az X változó értéke nulla, és ugyanakkor az Y változó értéke eggyel egyenlő; B - azon esetek száma, amikor az X és Y változók egyidejűleg egyenértékűek; C azon esetek száma, amikor az X és Y változók egyidejűleg nullával egyenlőek; D azon alkalmak száma, amikor az X változó értéke eggyel egyenlő, ugyanakkor az Y változó értéke nullával egyenlő. 6.2. táblázat Általános készenléti táblázat X funkció Általánosságban elmondható, hogy a dichotóm adatok Pearson-korrelációs együtthatójának képlete 6.3. táblázat Példa az adatokra dichotóm léptékben Helyettesítsük be a vizsgált példának megfelelő kontingencia táblázat adatait (lásd 6.4. táblázat) a képletbe: Így a kiválasztott példa Pearson-korrelációs együtthatója 0,32, vagyis a hallgatók családi állapota és az egyetemről való kizárás ténye közötti kapcsolat elhanyagolható. 2. példa Ha mindkét változót sorrendi skálán mérjük, akkor a Spearman-féle rangkorrelációs együtthatót (Rs) használjuk az asszociáció mértékeként. A képlet alapján számítják ki ahol Rs Spearman rangkorrelációs együtthatója; Di az összehasonlított objektumok rangsorai közötti különbség; N az összehasonlított objektumok száma. A Spearman-együttható értéke -1 és + 1 között változik. Az első esetben egyértelmű, de ellentétes irányú kapcsolat van a vizsgált változók között (az egyik értékének növekedésével a másiké csökken). A másodikban az egyik változó értékének növekedésével a második változó értéke arányosan növekszik. Ha az Rs értéke nulla, vagy közel van hozzá, akkor nincs szignifikáns kapcsolat a változók között. A Spearman-együttható kiszámítására példaként a 6.5. táblázat adatait használjuk. 6.5. táblázat Az együttható érték számításának adatai és közbenső eredményei rangkorreláció Rs Minőségek Szakértő által kiosztott rangok Rangkülönbség rangkülönbség négyzet –1 A rangkülönbségek négyzetes összege Di = 22 Helyettesítse a példaadatokat a Smirman-együttható képletébe: A számítás eredményei alapján megállapítható, hogy a vizsgált változók között meglehetősen markáns kapcsolat van. Tudományos hipotézis statisztikai igazolása. A kísérleti befolyás statisztikai megbízhatóságának bizonyítása jelentősen eltér a matematikai és a formális logikai bizonyításoktól, ahol a következtetések inkább univerzális jellegűek: a statisztikai bizonyítékok nem olyan szigorúak és véglegesek - mindig megengedik a következtetések tévedésének kockázatát, ezért egy adott következtetés érvényességét nem statisztikai módszerekkel igazolják véglegesen, de a hipotézis elfogadásának sajátos valószínűségének mértéke. Egy pedagógiai hipotézist (egyik vagy másik módszer előnyére vonatkozó tudományos feltételezést stb.) a statisztikai elemzés során lefordítanak a statisztikatudomány nyelvére, és legalább két statisztikai hipotézisben újrafogalmazzák. Az első (fő) ún null hipotézist(H 0), amelyben a kutató a kiinduló helyzetéről beszél. Úgy tűnik, (a priori) kijelenti, hogy az új (ő általa, kollégái vagy ellenzői által javasolt) módszernek nincsenek előnyei, ezért a kutató pszichológiailag már a kezdetektől készen áll az őszinte tudományos álláspontra: az új és a régi módszerek közötti különbséget nullával egyenlőnek nyilvánítják. Egy másikban alternatív hipotézis(H 1) feltételezzük az új módszer előnyeit. Néha több alternatív hipotézist is felállítanak megfelelő jelöléssel. Például a régi módszer előnyeiről szóló hipotézis (H 2). Alternatív hipotéziseket akkor és csak akkor fogadunk el, ha a nullhipotézist megcáfoljuk. Ez olyan esetekben fordul elő, amikor a különbségek, mondjuk, a kísérleti és a kontrollcsoport számtani átlagában olyan szignifikánsak (statisztikailag szignifikánsak), hogy a nullhipotézis elutasítása és az alternatíva elfogadása esetén a hiba kockázata nem haladja meg a három elfogadott közül az egyiket. szignifikancia szintek statisztikai következtetés: - az első szint - 5% (a tudományos szövegekben néha p \u003d 5% vagy a? 0,05 írnak, ha megosztásban mutatják be), ahol a következtetésben a hiba kockázata száz elméletileg lehetséges hasonló kísérletből öt esetben megengedett, az alanyok szigorúan véletlenszerű kiválasztásával minden kísérlethez; - a második szint - 1%, azaz ennek megfelelően a tévedés kockázata csak egy esetben megengedett a százból (a? 0,01, azonos követelményekkel); - a harmadik szint - 0,1%, azaz a tévedés kockázata ezerből csak egy esetben megengedett (a? 0,001). Az utolsó szignifikanciaszint nagyon magas követelményeket támaszt a kísérleti eredmények megbízhatóságának igazolásával szemben, ezért ritkán alkalmazzák. A kísérleti és a kontrollcsoport számtani átlagának összehasonlításakor nem csak az a fontos, hogy melyik átlag nagyobb, hanem az is, hogy mennyivel nagyobb. Minél kisebb a különbség köztük, annál elfogadhatóbb lesz a nullhipotézis a statisztikailag szignifikáns (szignifikáns) különbségek hiányáról. Ellentétben a hétköznapi tudat szintjén való gondolkodással, amely a tapasztalat eredményeként kapott átlagok különbségét hajlamos tényként és következtetési alapként felfogni, a statisztikai következtetés logikájában jártas tanár-kutató ilyenkor nem fog kapkodni. Valószínűleg azt feltételezi, hogy a különbségek véletlenszerűek, nullhipotézist állít fel a kísérleti és a kontrollcsoport eredményeiben szignifikáns különbségek hiányáról, és csak a nullhipotézis megcáfolása után fogadja el az alternatívát. Így a tudományos gondolkodás keretein belüli különbségek kérdése egy másik síkra kerül át. Nem csak a különbségekben van a lényeg (szinte mindig léteznek), hanem ezeknek a különbségeknek a nagyságában, és így a különbség és a határ meghatározásában is, ami után azt lehet mondani: igen, a különbségek nem véletlenek, hanem statisztikailag szignifikánsak, ami azt jelenti, hogy e két csoport alanyai a kísérlet után már nem egy (mint korábban), hanem két különböző általános populációba tartoznak szignifikánsan, és hogy a hallgatók potenciális felkészültségi szintjeihez fog tartozni. Ezen különbségek határainak bemutatása érdekében az ún általános paraméterek becslései. Vizsgáljuk meg egy konkrét példa segítségével (lásd a 6.6. táblázatot), hogy a matematikai statisztikák hogyan használhatók a nullhipotézis megcáfolására vagy megerősítésére. Tegyük fel, hogy meg kell határozni, hogy a tanulók csoportos tevékenységének eredményessége függ-e a vizsgált csoporton belüli interperszonális kapcsolatok fejlettségi szintjétől. Nullhipotézisként azt a feltételezést terjesztik elő, hogy ilyen függőség nem létezik, alternatívaként pedig létezik függőség. Ebből a célból két csoportban hasonlítják össze a tevékenységek hatékonyságának eredményeit, amelyek közül az egyik ebben az esetben kísérleti csoportként, a másik pedig kontrollcsoportként működik. Annak meghatározásához, hogy az első és a második csoport teljesítménymutatóinak átlagértékei közötti különbség szignifikáns-e (szignifikáns), ki kell számítani ennek a különbségnek a statisztikai szignifikanciáját. Ehhez használhatja a t - Student-kritériumot. Kiszámítása a következő képlettel történik: ahol X 1 és X 2 - az 1. és 2. csoport változóinak számtani átlaga; M 1 és M 2 az átlagos hibák értékei, amelyeket a következő képlettel számítanak ki: ahol a (2) képlettel kiszámított négyzetes átlag. Határozzuk meg az első sor (kísérleti csoport) és a második sor (kontrollcsoport) hibáit: A t - kritérium értékét a következő képlettel találjuk meg: A t-kritérium értékének kiszámítása után egy speciális táblázat segítségével meg kell határozni az átlagos teljesítménymutatók közötti különbségek statisztikai szignifikancia szintjét a kísérleti és a kontrollcsoportban. Minél nagyobb a t-kritérium értéke, annál nagyobb a különbségek jelentősége. Ehhez összehasonlítjuk a számított t-t a táblázatos t-vel. A táblázatos értéket a kiválasztott konfidenciaszint (p = 0,05 vagy p = 0,01) figyelembevételével választjuk ki, valamint a szabadsági fokok számától függően, amelyet a képlet határozza meg: ahol U a szabadsági fokok száma; N 1 és N 2 - a mérések száma az első és a második sorban. Példánkban U = 7 + 7 -2 = 12. 6.6. táblázat A statisztikai szignifikancia számításának adatai és közbenső eredményei Átlagos különbségek Kísérleti csoport Ellenőrző csoport A teljesítmény értéke A t tábla - kritérium esetén azt találjuk, hogy a t táblázat értéke. = 3,055 az egy százalékos szinthez (o A tanár-kutatónak azonban emlékeznie kell arra, hogy az átlagértékek különbségének statisztikai szignifikancia megléte fontos, de nem az egyetlen érv a jelenségek vagy változók közötti kapcsolat (függőség) megléte vagy hiánya mellett. Ezért egy esetleges összefüggés mennyiségi vagy tartalmi alátámasztására más érveket is be kell vonni. Az adatelemzés többdimenziós módszerei. A nagyszámú változó közötti kapcsolat elemzése többváltozós statisztikai feldolgozási módszerekkel történik. Az ilyen módszerek alkalmazásának célja rejtett minták láthatóvá tétele, a változók közötti leglényegesebb összefüggések kiemelése. Példák az ilyen többváltozós statisztikai módszerekre: - faktoranalízis; - klaszteranalízis; – varianciaanalízis; - regresszió analízis; – látens szerkezeti elemzés; – többdimenziós méretezés és mások. Faktoranalízis a tényezők azonosítása és értelmezése. A faktor egy általánosított változó, amely lehetővé teszi az információk egy részének összecsukását, azaz érthető formában történő bemutatását. Például a személyiség faktorelmélete a viselkedés számos általánosított jellemzőjét azonosítja, amelyeket ebben az esetben személyiségvonásoknak nevezünk. klaszteranalízis lehetővé teszi a vezető jellemző és a jellemzőkapcsolatok hierarchiájának kiemelését. Varianciaanalízis- statisztikai módszer, amellyel egy vagy több, egyidejűleg ható és független változót tanulmányoznak egy megfigyelt tulajdonság variabilitására. Sajátossága, hogy a megfigyelt jellemző csak mennyiségi, míg a magyarázó jellemzők mennyiségi és minőségi is lehetnek. Regresszió analízis lehetővé teszi az eredő attribútum (magyarázott) változásainak átlagos értékének mennyiségi (numerikus) függését egy vagy több attribútum (magyarázó változó) változásaitól. Általános szabály, hogy ezt a fajta elemzést akkor használják, amikor meg kell találni, hogy egy attribútum átlagos értéke mennyivel változik, amikor egy másik attribútum eggyel változik. Látens szerkezeti elemzés elemző és statisztikai eljárások összességét képviseli a rejtett változók (jellemzők) azonosítására, valamint a köztük lévő kapcsolatok belső szerkezetére. Lehetővé teszi a szociálpszichológiai és pedagógiai jelenségek közvetlenül nem megfigyelhető jellemzői összetett összefüggéseinek megnyilvánulási formáinak feltárását. A látens elemzés alapja lehet ezen kapcsolatok modellezésének. Többdimenziós méretezés vizuális értékelést ad néhány objektum közötti hasonlóságról vagy különbségről, amelyet számos különböző változó ír le. Ezeket a különbségeket a becsült objektumok távolságaként ábrázoljuk egy többdimenziós térben. 3. A pszichológiai és pedagógiai eredmények statisztikai feldolgozása kutatás Minden vizsgálatnál mindig fontos a vizsgált tárgyak tömeges jellegének és reprezentativitásának (reprezentativitásának) biztosítása. A probléma megoldására általában matematikai módszerekhez folyamodnak a vizsgálandó objektumok (válaszadói csoportok) minimális méretének kiszámításához, hogy ez alapján objektív következtetéseket lehessen levonni. Az elsődleges egységek lefedettségének foka szerint a statisztika a vizsgálatokat folyamatosra bontja, amikor a vizsgált jelenség összes egységét vizsgálják, és szelektívre, ha az érdeklődésre számot tartó sokaságnak csak egy részét, valamilyen tulajdonság szerint vesszük. A kutatónak nem mindig van lehetősége a jelenségek teljes halmazának tanulmányozására, pedig erre folyamatosan törekedni kell (nincs elég idő, forrás, szükséges feltételek stb.); másrészt gyakran egyszerűen nincs szükség folyamatos vizsgálatra, mivel az elsődleges egységek egy részének tanulmányozása után a következtetések kellően pontosak lesznek. A szelektív kutatási módszer elméleti alapja a valószínűségelmélet és a nagy számok törvénye. Annak érdekében, hogy a tanulmány elegendő számú tényt, megfigyelést tartalmazzon, egy kellően nagy számokat tartalmazó táblázatot használnak. Ebben az esetben a kutatónak meg kell határoznia a valószínűség nagyságát és a megengedett hiba nagyságát. Például a megfigyelések eredményeként levonható következtetésekben az elméleti feltevésekhez képest ne haladja meg a 0,05-öt pozitívan és negatívan (azaz 100-ból legfeljebb 5 esetben tévedhetünk). Ekkor a kellően nagy számok táblázata szerint (lásd 6.7. táblázat) azt találjuk, hogy a helyes következtetés 10-ből 9 esetben tehető le, ha a megfigyelések száma legalább 270, 100-ból 99 esetben, ha legalább 663 megfigyelés van, stb. Így a megfigyelések pontosságának és valószínűségének növekedésével a következtetések levonása szükséges. Egy pszichológiai és pedagógiai vizsgálatban azonban nem szabad túlzottan nagynak lennie. 300-500 megfigyelés gyakran elégséges a szilárd következtetésekhez. A mintanagyság meghatározásának ez a módszere a legegyszerűbb. A matematikai statisztikának vannak bonyolultabb módszerei is a szükséges mintahalmazok kiszámítására, amelyekkel a szakirodalom részletesen foglalkozik. A tömegjelleg követelményeinek való megfelelés azonban még nem biztosítja a következtetések megbízhatóságát. Akkor lesznek megbízhatóak, ha a megfigyelésre választott egységek (beszélgetések, kísérletek stb.) kellően reprezentálják a vizsgált jelenségosztályt. 6.7. táblázat Rövid táblázat kellően nagy számokkal Érték valószínűségek Megengedhető A megfigyelési egységek reprezentativitását elsősorban véletlenszámtáblázatok segítségével történő véletlenszerű kiválasztása biztosítja. Tegyük fel, hogy a rendelkezésre álló 200-ból 20 képzési csoportot kell meghatározni egy tömeges kísérlet elvégzéséhez. Ehhez összeállítják az összes csoport listáját, amely meg van számozva. Ezután 20 számot húzunk a véletlen számok táblázatából, bármely számtól kezdve, bizonyos időközönként. Ez a 20 véletlenszám a számok megfigyelésével határozza meg azokat a csoportokat, amelyekre a kutatónak szüksége van. Az objektumok véletlenszerű kiválasztása az általános (általános) sokaságból ad okot annak állítására, hogy az egységek mintapopulációjának vizsgálata során kapott eredmények nem térnek el élesen azoktól, amelyek az egységek teljes sokaságának vizsgálata esetén elérhetőek lennének. A pszichológiai és pedagógiai kutatások gyakorlatában nemcsak egyszerű véletlenszerű szelekciókat alkalmaznak, hanem bonyolultabb kiválasztási módszereket is: rétegzett véletlenszerű szelekciót, többlépcsős szelekciót stb. A kutatás matematikai és statisztikai módszerei is eszközei az új tényanyag megszerzésének. Erre a célra olyan sablontechnikákat alkalmaznak, amelyek növelik a kérdőíves kérdés informatív képességét és a skálázást, amely lehetővé teszi mind a kutató, mind az alanyok cselekvéseinek pontosabb értékelését. A skálák az egyes pszichológiai és pedagógiai jelenségek objektív és pontos diagnosztizálásának és intenzitásának mérésének szükségessége miatt merültek fel. A skálázás lehetővé teszi a jelenségek racionalizálását, mindegyik számszerűsítését, a vizsgált jelenség legalacsonyabb és legmagasabb szintjének meghatározását. Tehát a hallgatók kognitív érdeklődésének tanulmányozásakor meg lehet határozni a határaikat: nagyon nagy érdeklődés - nagyon gyenge érdeklődés. E határok között vezessen be néhány lépést, amelyek létrehozzák a kognitív érdeklődési körök skáláját: nagyon nagy érdeklődés (1); nagy érdeklődés (2); közepes (3); gyenge (4); nagyon gyenge (5). A pszichológiai és pedagógiai kutatásokban különböző típusú skálákat alkalmaznak, pl. a) Háromdimenziós skála Nagyon aktív………………..10 Aktív………………………………5 Passzív………………………….0 b) Többdimenziós skála Nagyon aktív……………………..8 Közepes aktív…………………….6 Nem túl aktív……………4 Passzív…………………………..2 Teljesen passzív……………0 c) Kétoldali skála. Nagyon érdekel……………..10 Eléggé érdekel…………5 Közömbös……………………….0 Nem érdekel……………………..5 Egyáltalán nem érdekli………10 A numerikus besorolási skálák minden elemnek egy meghatározott numerikus megjelölést adnak. Tehát a hallgatók tanuláshoz való hozzáállásának, munkában való kitartásának, együttműködési készségének, stb. számszerű skálát készíthet a következő mutatók alapján: 1 - nem kielégítő; 2 - gyenge; 3 - közepes; A 4 az átlag feletti, az 5 az átlag feletti. Ebben az esetben a skála a következő formában jelenik meg (lásd: 6.8. táblázat): 6.8. táblázat Ha a numerikus skála bipoláris, akkor a bipoláris sorrendet a nulla értékkel a közepén használjuk: Fegyelem Fegyelmezetlenség Kimondva 5 4 3 2 1 0 1 2 3 4 5 Nem kimondva Az értékelési skálák grafikusan jeleníthetők meg. Ebben az esetben vizuális formában fejezik ki a kategóriákat. Ezenkívül a skála minden felosztását (lépését) verbálisan jellemzik. A vizsgált módszerek fontos szerepet játszanak a kapott adatok elemzésében és általánosításában. Lehetővé teszik a tények közötti különféle összefüggések, összefüggések megállapítását, a pszichológiai és pedagógiai jelenségek fejlődési irányzatainak azonosítását. A matematikai statisztika csoportosítási elmélete tehát segít meghatározni, hogy az összegyűjtött empirikus anyagból mely tények összehasonlíthatók, milyen alapon célszerű helyesen csoportosítani, és milyen megbízhatósági fokok lesznek. Mindez lehetővé teszi a tényekkel való önkényes manipulációk elkerülését és azok feldolgozására szolgáló program meghatározását. A céloktól és célkitűzésektől függően általában háromféle csoportosítást alkalmaznak: tipológiai, variációs és analitikus. Tipológiai csoportosítás akkor használatos, ha a beérkezett tényanyagot minőségileg homogén egységekre kell bontani (a fegyelemsértések számának megoszlása a tanulók különböző kategóriái között, a fizikai gyakorlatokra vonatkozó teljesítménymutatóik bontása tanulmányi évek szerint stb.). Ha szükséges, csoportosítsa az anyagot bármely változó (változó) attribútum értéke szerint - a tanulói csoportok teljesítményszint szerinti bontása, a feladatok elvégzésének százalékos aránya, a megállapított sorrend hasonló megsértése stb. – alkalmazta variációs csoportosítás, amely lehetővé teszi a vizsgált jelenség szerkezetének következetes megítélését. A csoportosítás elemző képe segít a vizsgált jelenségek (a tanulók felkészültségi fokának függése a különböző tanítási módszerektől, a végzett feladatok temperamentumra, képességekre stb.) való kapcsolatának megállapításában, egymásrautaltságuk és egymásrautaltságuk pontos számításban. Hogy mennyire fontos a kutató munkája az összegyűjtött adatok csoportosításában, azt bizonyítja, hogy ebben a munkában a hibák leértékelik a legátfogóbb és legértelmesebb információkat. Jelenleg a csoportosítás, a tipológia és az osztályozás matematikai alapjai a szociológiában kapták a legmélyebb fejlődést. A szociológiai kutatás korszerű tipológiai és osztályozási megközelítései és módszerei sikeresen alkalmazhatók a pszichológiában és a pedagógiában. A vizsgálat során az adatok végső általánosításának módszereit alkalmazzák. Az egyik a táblázatok összeállításának és tanulmányozásának technikája. Egy statisztikai értékre vonatkozó adatösszegzés összeállításakor ennek az értéknek az értékéből egy eloszlási sorozat (variációs sorozat) jön létre. Példa egy ilyen sorozatra (lásd a 6.9. táblázatot) az 500 arc mellkasának kerületére vonatkozó adatok összefoglalása. 6.9. táblázat Az adatok egyidejű összefoglalása két vagy több statisztikai értékre egy eloszlási táblázat összeállítását jelenti, amely felfedi egy statikus érték értékeinek eloszlását a többi érték által felvett értékek szerint. Szemléltetésképpen a 6.10. táblázatot adjuk meg, amely statisztikai adatok alapján készült a mellkas körméretére és ezen személyek súlyára vonatkozóan. 6.10. táblázat Mellkas kerülete cm-ben Az eloszlási táblázat képet ad a két érték közötti kapcsolatról és összefüggésről, nevezetesen: kis súly mellett a gyakoriságok a táblázat bal felső negyedében helyezkednek el, ami a kis mellkörfogatú személyek túlsúlyát jelzi. Ahogy a súly a középső érték felé növekszik, a frekvenciaeloszlás a lemez közepe felé mozdul el. Ez azt jelzi, hogy az átlagos testsúlyhoz közelebb álló emberek mellkaskörfogata szintén közel van az átlaghoz. A súly további növekedésével a frekvenciák a lemez jobb alsó negyedét kezdik elfoglalni. Ez azt jelzi, hogy az átlagosnál nagyobb testsúlyú embernél a mellkas kerülete is meghaladja az átlagos térfogatot. A táblázatból következik, hogy a megállapított kapcsolat nem szigorú (funkcionális), hanem valószínűségi, amikor az egyik mennyiség értékének változásával a másik trendként változik, merev, egyértelmű függés nélkül. Ilyen összefüggések és függőségek gyakran megtalálhatók a pszichológiában és a pedagógiában. Jelenleg ezeket általában korrelációs és regressziós elemzéssel fejezik ki. A variációs sorozatok és táblázatok képet adnak a jelenség statikájáról, míg a dinamika fejlődési sorozatokkal mutatható ki, ahol az első sor egymást követő szakaszokat vagy időintervallumokat tartalmaz, a második pedig az ezekben a szakaszokban kapott vizsgált statisztikai érték értékeit. Így feltárul a vizsgált jelenség növekedése, csökkenése vagy periodikus változása, feltárulnak tendenciái, mintázatai. A táblázatok kitölthetők abszolút értékekkel, vagy összegző számokkal (átlag, relatív). A statisztikai munka eredményei - a táblázatokon kívül gyakran grafikusan is ábrázolják diagramok, ábrák stb. formájában. A statisztikai értékek grafikus ábrázolásának fő módjai a következők: a pontok módszere, az egyenesek módszere és a téglalapok módszere. Egyszerűek és minden kutató számára hozzáférhetőek. Használatuk technikája a koordinátatengelyek rajzolása, a lépték beállítása, a szegmensek (pontok) kijelölése a vízszintes és függőleges tengelyeken. Az egy statisztikai mennyiség értékeinek eloszlási sorozatát ábrázoló diagramok lehetővé teszik az eloszlási görbék felépítését. Két (vagy több) statisztikai mennyiség grafikus ábrázolása lehetővé teszi egy bizonyos görbe felület, az úgynevezett eloszlási felület kialakítását. A grafikus végrehajtás számos fejlesztése fejlesztési görbéket alkot. A statisztikai anyagok grafikus ábrázolása lehetővé teszi, hogy mélyebben behatoljunk a digitális értékek jelentésébe, megragadjuk egymásrautaltságukat és a vizsgált jelenségnek a táblázatban nehezen észrevehető sajátosságait. A kutató felszabadul a munka alól, amit el kellene végeznie ahhoz, hogy megbirkózzon a rengeteg számmal. A táblázatok és grafikonok fontosak, de csak az első lépések a statisztikai mennyiségek vizsgálatában. A fő módszer analitikus, matematikai képletekkel működik, amelyek segítségével az úgynevezett „általánosító mutatókat” származtatják, azaz összehasonlítható formában (relatív és átlagértékek, egyenlegek és indexek) adják meg az abszolút értékeket. Tehát a relatív értékek (százalékok) segítségével meghatározzák az elemzett sokaság minőségi jellemzőit (például a kiváló hallgatók aránya az összes hallgatóhoz viszonyítva; a komplex berendezéseken végzett munka során a hallgatók mentális instabilitása által okozott hibák száma az összes hibák számához stb.). Vagyis a kapcsolatok feltárulnak: részek az egészhez (fajsúly), tagok az összeghez (halmazstruktúra), a halmaz egy része a másik részéhez; az időbeli változások dinamikájának jellemzése stb. Mint látható, a statisztikai számítási módszerek legáltalánosabb ötlete is azt sugallja, hogy ezek a módszerek nagy lehetőségeket rejtenek magukban az empirikus anyagok elemzésében és feldolgozásában. Természetesen a matematikai apparátus szenvtelenül tud mindent feldolgozni, amit a kutató belehelyez, megbízható adatokat és szubjektív sejtéseket egyaránt. Éppen ezért minden kutató számára szükséges a felhalmozott empirikus anyagot egységben feldolgozó matematikai apparátus a vizsgált jelenség minőségi jellemzőinek alapos ismeretével. Csak ebben az esetben lehetséges a minőségi, tárgyilagos tényanyag kiválasztása, annak minősített feldolgozása, megbízható végső adatok beszerzése. Ez egy rövid leírás a pszichológia és pedagógia problémáinak tanulmányozására leggyakrabban használt módszerekről. Hangsúlyozni kell, hogy önmagában véve egyik vizsgált módszer sem mondhatja magát univerzálisnak, amely teljes mértékben garantálja a kapott adatok objektivitását. Így a válaszadók megkérdezésével kapott válaszokban a szubjektivizmus elemei nyilvánvalóak. A megfigyelések eredményei általában nem mentesek magának a kutatónak a szubjektív értékelésétől. A különböző dokumentumokból vett adatok e dokumentáció (különösen a személyes iratok, használt okmányok stb.) megbízhatóságának egyidejű ellenőrzését igénylik. Ezért minden kutatónak egyrészt arra kell törekednie, hogy egy adott módszer alkalmazásának technikáját fejlessze, másrészt a különböző módszerek komplex, egymást ellenőrző alkalmazására ugyanazon probléma vizsgálatára. A teljes módszerrendszer birtoklása lehetővé teszi racionális kutatási módszertan kialakítását, áttekinthető szervezését és lebonyolítását, jelentős elméleti és gyakorlati eredmények elérését. Hivatkozások. Shevandrin N.I. Szociálpszichológia az oktatásban: Tankönyv. 1. rész. A szociálpszichológia fogalmi és alkalmazott alapjai. – M.: VLADOS, 1995. 2. Davydov V.P. A pedagógiai kutatás módszertani, módszertani és technológiai alapjai: Tudományos és módszertani kézikönyv. - M .: FSB Akadémia, 1997. A VÉLETLENSZERŰ ÉRTÉKEK ÉS AZOK FORRÁSÁNAK TÖRVÉNYEI. Véletlen olyan mennyiségnek nevezzük, amely a véletlenszerű körülmények kombinációjától függően vesz fel értékeket. Megkülönböztetni diszkrét
és véletlenszerű folyamatos
mennyiségeket. Diszkrét Egy mennyiséget akkor hívunk, ha megszámlálható értékhalmazt vesz fel. ( Példa: az orvosi rendelőben lévő betegek száma, az oldalankénti betűk száma, az adott kötetben lévő molekulák száma). folyamatos Olyan mennyiségnek nevezzük, amely egy bizonyos intervallumon belül értéket vehet fel. ( Példa: levegő hőmérséklet, testtömeg, embermagasság stb.) elosztási törvény A valószínűségi változó ennek a mennyiségnek és az ezeknek az értékeknek megfelelő valószínűségeknek (vagy előfordulási gyakoriságoknak) lehetséges értékeinek halmaza. PÉLDA: A VÉLETLENSZERŰ ÉRTÉKEK NUMERIKUS JELLEMZŐI. Sok esetben egy valószínűségi változó eloszlásával együtt vagy helyette numerikus paraméterekkel, ún. egy valószínűségi változó numerikus jellemzői
. Ezek közül a leggyakrabban használtak: 1
.Várható érték -
Egy valószínűségi változó (átlagértéke) az összes lehetséges értéke szorzata és ezen értékek valószínűsége: 2
.Diszperzió
véletlen változó: 3
.Szórás
: A HÁROM SZIGMA szabály - ha egy valószínűségi változót a normális törvény szerint osztunk el, akkor ennek az értéknek az abszolút értékben kifejezett átlagtól való eltérése nem haladja meg a szórás háromszorosát GAUSS ZÓNA – NORMÁL FORGALMAZÁSI TÖRVÉNY Gyakran vannak elosztva az értékek normális törvény
(Gauss törvénye). fő jellemzője
: ez az a korlátozó törvény, amelyhez az elosztás más törvényei közelednek. Egy valószínűségi változó normális eloszlású, ha az valószínűségi sűrűség
úgy néz ki, mint a: M(X)- egy valószínűségi változó matematikai elvárása; s- szórás. Valószínűségi sűrűség(eloszlási függvény) megmutatja, hogyan változik az intervallumhoz kapcsolódó valószínűség dx
valószínűségi változó, magának a változónak az értékétől függően: A MATEMATIKAI STATISZTIKA ALAPVETŐ FOGALMAI Matematikai statisztika- az alkalmazott matematikának egy ága, amely közvetlenül szomszédos a valószínűségelmélettel. A fő különbség a matematikai statisztika és a valószínűségszámítás között az, hogy a matematikai statisztika nem az eloszlási törvényekre és a valószínűségi változók numerikus jellemzőire vonatkozó műveleteket veszi figyelembe, hanem közelítő módszereket ezeknek a törvényeknek és a numerikus jellemzőknek a kísérleti eredményeken alapuló megtalálására. Alapfogalmak A matematikai statisztikák a következők: 1.
Általános népesség;
2.
minta;
3.
variációs sorozat;
4.
divat;
5.
középső;
6.
százalékos,
7.
frekvencia sokszög,
8.
oszlopdiagram.
Népesség- egy nagy statisztikai sokaság, amelyből a kutatási objektumok egy részét kiválasztják (Példa: a régió teljes lakossága, a város egyetemistái stb.) Minta (minta sokaság)- az általános sokaságból kiválasztott objektumok halmaza. Variációs sorozat- statisztikai eloszlás, amely változatokból (egy valószínűségi változó értékeiből) és a hozzájuk tartozó gyakoriságokból áll. Példa: x- egy valószínűségi változó értéke (10 éves lányok tömege); m- előfordulási gyakoriság. Divat– a valószínűségi változó értéke, amely a legmagasabb előfordulási gyakoriságnak felel meg. (A fenti példában a 24 kg a divat leggyakoribb értéke: m = 20). Középső- az eloszlást felére osztó valószínűségi változó értéke: az értékek fele a mediántól jobbra, a fele (nem több) balra található. Példa: 1, 1, 1, 1, 1. 1, 2, 2, 2, 3
, 3, 4, 4, 5, 5, 5, 5, 6, 6, 7
, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8
, 8, 9, 9, 9, 10, 10, 10, 10, 10, 10 A példában egy valószínűségi változó 40 értékét figyeljük meg. Minden érték növekvő sorrendben van elrendezve, figyelembe véve előfordulásuk gyakoriságát. Látható, hogy a 40 értékből 20 (a fele) a kiválasztott 7-es értéktől jobbra található. Tehát a 7 a medián. A szórás jellemzésére azokat az értékeket találjuk, amelyek nem haladták meg a mérési eredmények 25 és 75%-át. Ezeket az értékeket 25-nek és 75-nek nevezik százalékos
. Ha a medián felezi az eloszlást, akkor a 25. és 75. percentilis negyedével leválik tőle. (Maga a medián egyébként az 50. percentilisnek tekinthető.) Ahogy a példából is látható, a 25. és 75. percentilis 3, illetve 8. használat diszkrét
(pont) statisztikai eloszlás és folyamatos
(intervallum) statisztikai eloszlás. Az érthetőség kedvéért a statisztikai eloszlásokat grafikusan ábrázoltuk az űrlapon frekvencia sokszög
vagy - hisztogramok
. Frekvencia sokszög- szaggatott vonal, melynek szakaszai pontokat kapcsolnak össze koordinátákkal ( x 1, m 1), (x2,m2), ..., vagy for relatív frekvenciák sokszöge
- koordinátákkal ( x 1, p * 1), (x 2, p * 2), ...(1. ábra). Fig.1 Fig.2 Frekvencia hisztogram- egy egyenesre épített szomszédos téglalapok halmaza (2. ábra), a téglalapok alapja azonos és egyenlő dx
, és a magasságok megegyeznek a frekvencia arányával dx
, vagy R*
Nak nek dx
(valószínűségi sűrűség). Példa: Frekvencia sokszög A relatív gyakoriság és az intervallum szélességének arányát ún valószínűségi sűrűség f(x)=m i / n dx = p* i / dx
Példa hisztogram felépítésére . Használjuk az előző példa adatait. 1. Az osztályközök számának kiszámítása Ahol n
- megfigyelések száma. A mi esetünkben n = 100
. Ennélfogva: 2. Az intervallum szélességének kiszámítása dx
: 3. Intervallumsorozat készítése: oszlopdiagram


 - az első eredménysorhoz.
- az első eredménysorhoz. - a második eredménysorhoz.
- a második eredménysorhoz. - az első sorhoz.
- az első sorhoz. - a második sorhoz.
- a második sorhoz. - az első sorhoz.
- az első sorhoz. - a második sorhoz.
- a második sorhoz.





 És
És 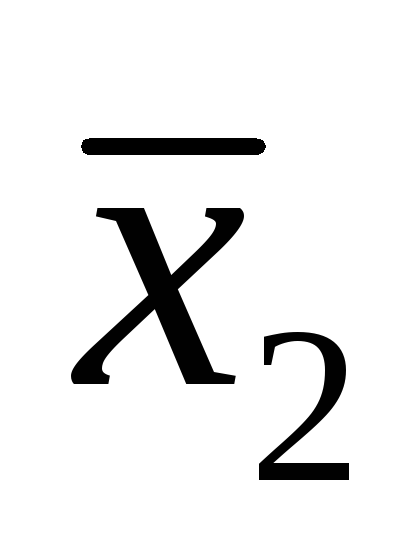 szignifikáns, és a minta nem tartozik ugyanahhoz az általános sokasághoz. Ha t exp<
t крит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n 1 +n 2
результатов.
szignifikáns, és a minta nem tartozik ugyanahhoz az általános sokasághoz. Ha t exp<
t крит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n 1 +n 2
результатов.
![]()
A tanulmány megszervezése
3.1.1 A matematikai statisztika feladatai és módszerei
3.1.2 Mintatípusok
 minta.
minta. ,
,
 .
. :
: .
.
 .
.




 .
. . (3.2)
. (3.2)
–1
–1
x x 1 x2 x 3 x4 ...
x n
p 1. o 2. o 3. o 4. o ...
p n
x x 1 x2 x 3 x4 ...
x n
m m 1 m2 m 3 m4 ...
m n


X, kg
m

 m m i /n f(x)
m m i /n f(x)x, kg 2,7
2,8
2,9
3,0
3,1
3,2
3,3
3,4
3,5
3,6
3,7
3,8
3,9
4,0
4,1
4,2
4,3
4,4
m

![]()
 ,
, 
dx 2.7-2.9
2.9-3.1
3.1-3.3
3.3-3.5
3.5-3.7
3.7-3.9
3.9-4.1
4.1-4.3
4.3-4.5
m
f(x) 0.3
0.75
1.25
0.85
0.55
0.6
0.4
0.25
0.05




