
Ne všechny jevy se měří v kvantitativní škále jako 1, 2, 3 ... 100500 ... Ne vždy může jev nabývat nekonečného nebo velkého počtu různých stavů. Například pohlaví osoby může být buď M nebo F. Střelec buď zasáhne cíl, nebo mine. Hlasovat můžete „pro“ nebo „proti“ atd. a tak dále. Jinými slovy, taková data odrážejí stav alternativního atributu – buď „ano“ (událost nastala) nebo „ne“ (událost nenastala). Nadcházející událost (pozitivní výsledek) se také nazývá „úspěch“.
Experimenty s takovými daty se nazývají Bernoulliho schéma, na počest slavného švýcarského matematika, který zjistil, že při velkém počtu pokusů má poměr pozitivních výsledků k celkovému počtu pokusů tendenci k pravděpodobnosti výskytu této události.
Alternativní proměnná funkcí
Aby bylo možné při analýze použít matematický aparát, měly by být výsledky takových pozorování zapsány v číselné formě. K tomu je kladnému výsledku přiřazeno číslo 1, zápornému 0. Jinými slovy, máme co do činění s proměnnou, která může nabývat pouze dvou hodnot: 0 nebo 1.
Jaký prospěch z toho lze získat? Vlastně ne méně než z běžných dat. Je tedy snadné spočítat počet kladných výsledků - stačí sečíst všechny hodnoty, tzn. vše 1 (úspěch). Můžete jít dále, ale k tomu je třeba zavést několik notací.
První věc, kterou je třeba poznamenat, je, že pozitivní výsledky (které se rovnají 1) mají určitou pravděpodobnost výskytu. Například získání hlav při hodu mincí je ½ nebo 0,5. Tato pravděpodobnost se tradičně označuje latinkou p. Pravděpodobnost výskytu alternativní události tedy je 1-p, který je také označen q, to je q = 1 – p. Tato označení mohou být vizuálně systematizována ve formě variabilní distribuční desky X.
Získali jsme seznam možných hodnot a jejich pravděpodobnosti. lze vypočítat očekávaná hodnota A disperze. Očekávání je součet součinů všech možných hodnot a jejich odpovídajících pravděpodobností:
![]()
Vypočítejme očekávanou hodnotu pomocí zápisu v tabulkách výše.
Ukazuje se, že matematické očekávání alternativního znaménka se rovná pravděpodobnosti této události - p.
Nyní definujme, jaký je rozptyl alternativní funkce. Rozptyl je průměrný čtverec odchylek od matematického očekávání. Obecný vzorec (pro diskrétní data) je:
Proto rozptyl alternativní funkce:

Je snadné vidět, že tato disperze má maximum 0,25 (at p=0,5).
Směrodatná odchylka - kořen rozptylu:
Maximální hodnota nepřesahuje 0,5.
Jak vidíte, jak matematické očekávání, tak i rozptyl alternativního znaménka mají velmi kompaktní podobu.
Binomické rozdělení náhodné veličiny
Podívejme se na situaci z jiného úhlu. Koho vlastně zajímá, že průměrná ztráta hlav na jeden los je 0,5? Ani si to nelze představit. Zajímavější je vznést otázku počtu hlav přicházejících na daný počet hodů.
Jinými slovy, výzkumník se často zajímá o pravděpodobnost určitého počtu úspěšných událostí. Může to být počet vadných produktů v testované šarži (1 – vadný, 0 – dobrý) nebo počet uzdravených produktů (1 – zdravý, 0 – nemocný) atd. Počet takových „úspěchů“ se bude rovnat součtu všech hodnot proměnné X, tj. počet jednotlivých výsledků.
Náhodná hodnota B se nazývá binomický a nabývá hodnot od 0 do n(na B= 0 - všechny části jsou dobré, s B = n- všechny díly jsou vadné). Předpokládá se, že všechny hodnoty X nezávisle na sobě. Zvažte hlavní charakteristiky binomické proměnné, to znamená, že stanovíme její matematické očekávání, rozptyl a distribuci.
Očekávání binomické proměnné je velmi snadné získat. Matematické očekávání součtu hodnot je součtem matematických očekávání každé přidané hodnoty a je pro všechny stejné, proto:
Například očekávaný počet hlav na 100 hodů je 100 × 0,5 = 50.
Nyní odvodíme vzorec pro rozptyl binomické proměnné. Rozptyl součtu nezávislých náhodných veličin je součtem rozptylů. Odtud
Směrodatná odchylka, resp
Za 100 hodů mincí standardní odchylka počet orlů je
A nakonec uvažujme rozdělení binomické veličiny, tzn. pravděpodobnost, že náhodná hodnota B bude trvat různé významy k, Kde 0≤k≤n. Za minci by tento problém mohl znít takto: jaká je pravděpodobnost získání 40 hlav při 100 hodech?
Abychom pochopili metodu výpočtu, představme si, že mincí se hodí pouze 4x. Každá strana může pokaždé vypadnout. Ptáme se sami sebe: jaká je pravděpodobnost získání 2 hlav ze 4 hodů. Každý hod je na sobě nezávislý. To znamená, že pravděpodobnost získání jakékoli kombinace se bude rovnat součinu pravděpodobností daného výsledku pro každý jednotlivý hod. Nechť O jsou hlavy a P ocasy. Pak může například jedna z kombinací, která nám vyhovuje, vypadat jako OOPP, tedy:

Pravděpodobnost takové kombinace se rovná součinu dvou pravděpodobností příchodu hlav a dvou dalších pravděpodobností nedostavení se hlav (opačná událost vypočtena jako 1-p), tj. 0,5×0,5×(1-0,5)×(1-0,5)=0,0625. To je pravděpodobnost jedné z kombinací, která nám vyhovuje. Ale otázka se týkala celkového počtu orlů a ne nějakého konkrétního pořadí. Pak je potřeba sečíst pravděpodobnosti všech kombinací, ve kterých jsou právě 2 orli. Je jasné, že jsou všechny stejné (součin se změnou místa faktorů nemění). Proto je třeba vypočítat jejich počet a poté vynásobit pravděpodobností jakékoli takové kombinace. Počítejme všechny kombinace 4 hodů 2 orlů: RROO, RORO, ROOR, ORRO, OROR, OORR. Pouze 6 možností.

Požadovaná pravděpodobnost získání 2 hlav po 4 hodech je tedy 6×0,0625=0,375.
Počítání tímto způsobem je však zdlouhavé. Již za 10 mincí bude velmi obtížné získat celkový počet možností hrubou silou. Proto chytří lidé dávno vynalezl vzorec, který počítá počet různých kombinací n prvky podle k, Kde n je celkový počet prvků, k je počet prvků, jejichž možnosti uspořádání se počítají. Kombinační vzorec z n prvky podle k je:
![]()
Podobné věci se odehrávají v sekci kombinatoriky. Posílám tam všechny, kteří si chtějí zlepšit své znalosti. Odtud, mimochodem, název binomického rozdělení (výše uvedený vzorec je koeficient rozšíření Newtonova binomu).
Vzorec pro určení pravděpodobnosti lze snadno zobecnit na libovolné číslo n A k. Výsledkem je, že vzorec binomického rozdělení má následující tvar.
Vynásobte počet odpovídajících kombinací pravděpodobností jedné z nich.
Pro praktické použití stačí jednoduše znát vzorec pro binomické rozdělení. A možná ani nevíte – níže je, jak určit pravděpodobnost pomocí Excelu. Ale je lepší to vědět.
Použijme tento vzorec k výpočtu pravděpodobnosti získání 40 hlav při 100 hodech:
Nebo jen 1,08 %. Pro srovnání, pravděpodobnost matematického očekávání tohoto experimentu, tedy 50 hlav, je 7,96 %. Maximální pravděpodobnost binomické hodnoty náleží hodnotě odpovídající matematickému očekávání.
Výpočet pravděpodobností binomického rozdělení v Excelu
Pokud používáte pouze papír a kalkulačku, pak jsou výpočty pomocí vzorce binomického rozdělení i přes absenci integrálů poměrně obtížné. Například hodnota 100! - má více než 150 znaků. Dříve i nyní se pro výpočet takových veličin používaly přibližné vzorce. V tuto chvíli je vhodné používat speciální software, např. MS Excel. Každý uživatel (i vzděláním humanista) si tedy snadno spočítá pravděpodobnost hodnoty binomicky rozdělené náhodné veličiny.
Pro konsolidaci materiálu použijeme prozatím Excel jako běžnou kalkulačku, tzn. Udělejme krok za krokem výpočet pomocí vzorce binomického rozdělení. Spočítejme si například pravděpodobnost získání 50 hlav. Níže je obrázek s kroky výpočtu a konečným výsledkem.

Jak vidíte, mezivýsledky jsou takového rozsahu, že se do buňky nevejdou, ačkoliv se používají všude jednoduché funkce typy: FACTOR (výpočet faktoriálu), POWER (umocnění čísla), stejně jako operátory násobení a dělení. Navíc je tento výpočet poněkud těžkopádný, v žádném případě není kompaktní, protože zapojeno mnoho buněk. A ano, je těžké na to přijít.
Obecně Excel poskytuje hotovou funkci pro výpočet pravděpodobností binomického rozdělení. Funkce je volána BINOM.DIST.

Počet úspěchů je počet úspěšných pokusů. Máme jich 50.
Počet pokusů - počet hodů: 100krát.
Pravděpodobnost úspěchu – pravděpodobnost získání hlav na jeden los je 0,5.
Integrální - je uvedena buď 1 nebo 0. Pokud 0, pak se vypočítá pravděpodobnost P(B=k); je-li 1, pak se vypočítá binomická distribuční funkce, tzn. součet všech pravděpodobností od B=0 před B=k včetně.
Stiskneme OK a dostaneme stejný výsledek jako výše, jen vše vypočítala jedna funkce.

Velmi pohodlně. Pro účely experimentu místo posledního parametru 0 vložíme 1. Dostaneme 0,5398. To znamená, že při 100 hodech mincí je pravděpodobnost získání hlav mezi 0 a 50 téměř 54 %. A zpočátku to vypadalo, že by to mělo být 50 %. Obecně se výpočty provádějí snadno a rychle.
Opravdový analytik musí rozumět tomu, jak se funkce chová (jaké je její rozložení), proto spočítejme pravděpodobnosti pro všechny hodnoty od 0 do 100. Tedy položme si otázku: jaká je pravděpodobnost, že nepadne ani jeden orel, že padne 1 orel, 2, 3, 50, 90 nebo 100. Výpočet je na následujícím obrázku. Modrá čára je samotné binomické rozdělení, červená tečka je pravděpodobnost určitého počtu úspěchů k.

Někdo by se mohl zeptat, není binomické rozdělení podobné... Ano, velmi podobné. Dokonce i De Moivre (v roce 1733) řekl, že u velkých vzorků se blíží binomické rozdělení (nevím, jak se tomu tehdy říkalo), ale nikdo ho neposlouchal. Teprve Gauss a poté Laplace po 60-70 letech znovuobjevili a pečlivě studovali normální zákon rozdělení. Výše uvedený graf jasně ukazuje, že maximální pravděpodobnost připadá na matematické očekávání a jak se od něj odchyluje, prudce klesá. Jako normální zákon.
Binomické rozdělení má velký praktický význam, vyskytuje se poměrně často. Pomocí Excelu se výpočty provádějí snadno a rychle.
Binomické rozdělení je jedním z nejdůležitějších rozdělení pravděpodobnosti pro diskrétně se měnící náhodnou veličinu. Binomické rozdělení je rozdělení pravděpodobnosti čísla m událost A PROTI n vzájemně nezávislá pozorování. Často událost A označované jako „úspěch“ pozorování a opačná událost – „neúspěch“, ale toto označení je velmi podmíněné.
Podmínky binomického rozdělení:
- provedeno celkem n zkoušky, ve kterých se event A může nebo nemusí nastat;
- událost A v každém z pokusů může nastat se stejnou pravděpodobností p;
- testy jsou vzájemně nezávislé.
Pravděpodobnost, že v n zkušební akce A přesně m krát, lze vypočítat pomocí Bernoulliho vzorce:
![]()
Kde p- pravděpodobnost výskytu události A;
q = 1 - p je pravděpodobnost, že dojde k opačné události.
Pojďme na to přijít proč binomické rozdělení souvisí s Bernoulliho vzorcem výše popsaným způsobem . Událost - počet úspěchů při n testy jsou rozděleny do několika možností, z nichž každá je úspěšná m pokusy, a neúspěch - v n - m testy. Zvažte jednu z těchto možností - B1 . Podle pravidla sčítání pravděpodobností násobíme pravděpodobnosti opačných událostí:
![]() ,
,
a označíme-li q = 1 - p, Že
![]() .
.
Stejnou pravděpodobnost bude mít jakákoli jiná možnost, ve které múspěch a n - m selhání. Počet takových možností se rovná počtu způsobů, kterými je to možné n test získat múspěch.
Součet pravděpodobností všech mčíslo akce A(čísla od 0 do n) se rovná jedné:
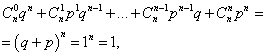
kde každý člen je členem Newtonova binomu. Proto se uvažované rozdělení nazývá binomické rozdělení.
V praxi je často nutné počítat pravděpodobnosti „maximálně múspěch v n testy“ nebo „alespoň múspěch v n testy". K tomu se používají následující vzorce.
Integrální funkce, tzn pravděpodobnost F(m), že v n pozorovací akce A už nepřijde m jednou, lze vypočítat pomocí vzorce:
Ve své řadě pravděpodobnost F(≥m), že v n pozorovací akce A přijďte alespoň m jednou, se vypočítá podle vzorce:
Někdy je pohodlnější vypočítat pravděpodobnost, že v n pozorovací akce A už nepřijde m krát, prostřednictvím pravděpodobnosti opačné události:
![]() .
.
Který ze vzorců použít, závisí na tom, který z nich obsahuje méně výrazů.
Charakteristiky binomického rozdělení se vypočítají pomocí následujících vzorců .
Očekávaná hodnota: .
disperze: .
Standardní odchylka: .
Binomické rozdělení a výpočty v MS Excel
Pravděpodobnost binomického rozdělení P n ( m) a hodnotu integrální funkce F(m) lze vypočítat pomocí funkce MS Excel BINOM.DIST. Okno pro příslušný výpočet je zobrazeno níže (klikněte levým tlačítkem myši pro zvětšení).

MS Excel vyžaduje zadání následujících údajů:
- počet úspěchů;
- počet testů;
- pravděpodobnost úspěchu;
- integrál - logická hodnota: 0 - pokud potřebujete vypočítat pravděpodobnost P n ( m) a 1 - je-li pravděpodobnost F(m).
Příklad 1 Manažer společnosti shrnul informace o počtu prodaných kamer za posledních 100 dní. V tabulce jsou shrnuty informace a vypočteny pravděpodobnosti, že se za den prodá určitý počet kamer.
Den končí ziskem, pokud se prodá 13 a více kamer. Pravděpodobnost, že den bude vypracován se ziskem:
![]()
Pravděpodobnost, že den bude odpracován bez zisku:

Pravděpodobnost, že je den odpracován se ziskem, nechť je konstantní a rovná se 0,61 a počet prodaných kamer za den nezávisí na dni. Pak můžete použít binomické rozdělení, kde událost A- den bude vypracován se ziskem, - bez zisku.
Pravděpodobnost, že ze 6 dnů bude vše vypracováno se ziskem:
![]() .
.
Stejný výsledek získáme pomocí funkce MS Excel BINOM.DIST (hodnota integrálu je 0):
P 6 (6 ) = BINOM.DIST(6; 6; 0,61; 0) = 0,052.
Pravděpodobnost, že ze 6 dnů budou 4 nebo více dnů odpracovány se ziskem:
Kde ![]() ,
,
![]() ,
,
Pomocí funkce MS Excel BINOM.DIST vypočítáme pravděpodobnost, že ze 6 dnů nebudou se ziskem dokončeny více než 3 dny (hodnota integrálu je 1):
P 6 (≤3 ) = BINOM.DIST(3; 6; 0,61; 1) = 0,435.
Pravděpodobnost, že ze 6 dnů bude vše vyřešeno se ztrátami:
![]() ,
,
Stejný ukazatel vypočítáme pomocí funkce MS Excel BINOM.DIST:
P 6 (0 ) = BINOM.DIST(0; 6; 0,61; 0) = 0,0035.
Vyřešte problém sami a pak se podívejte na řešení
Příklad 2 Urna obsahuje 2 bílé koule a 3 černé. Z urny se vyjme míč, nastaví se barva a vrátí se zpět. Pokus se opakuje 5x. Počet výskytů bílých kuliček je diskrétní náhodná veličina X, rozdělené podle binomického zákona. Sestavte zákon rozdělení náhodné veličiny. Určete modus, matematické očekávání a rozptyl.
Pokračujeme v řešení problémů společně
Příklad 3 Z kurýrní služby šel k objektům n= 5 kurýrů. Každý kurýr s pravděpodobností p= 0,3 je pro objekt pozdě bez ohledu na ostatní. Diskrétní náhodná veličina X- počet pozdních kurýrů. Sestrojte distribuční řadu této náhodné veličiny. Najděte jeho matematické očekávání, rozptyl, směrodatnou odchylku. Najděte pravděpodobnost, že se pro předměty zpozdí alespoň dva kurýři.
Teorie pravděpodobnosti je v našich životech neviditelně přítomná. Nevěnujeme tomu pozornost, ale každá událost v našem životě má tu či onu pravděpodobnost. Vzhledem k obrovskému množství možných scénářů je pro nás nutné určit nejpravděpodobnější a nejméně pravděpodobný z nich. Nejpohodlnější je analyzovat taková pravděpodobnostní data graficky. V tom nám může pomoci distribuce. Binomický je jedním z nejjednodušších a nejpřesnějších.
Než přistoupíme přímo k matematice a teorii pravděpodobnosti, pojďme si ujasnit, kdo jako první přišel s tímto typem rozdělení a jaká je historie vývoje matematického aparátu pro tento pojem.
Příběh
Pojem pravděpodobnosti je znám již od starověku. Starověcí matematici tomu však nepřikládali velký význam a dokázali pouze položit základy teorie, která se později stala teorií pravděpodobnosti. Vytvořili některé kombinatorické metody, které velmi pomohly těm, kteří později vytvořili a rozvinuli samotnou teorii.
Ve druhé polovině sedmnáctého století se začaly formovat základní pojmy a metody teorie pravděpodobnosti. Byly zavedeny definice náhodných veličin, metody pro výpočet pravděpodobnosti jednoduchých a některých komplexních nezávislých a závislých jevů. Takový zájem o náhodné proměnné a pravděpodobnosti byl diktován hazardem: každý chtěl vědět, jaké jsou jeho šance na výhru ve hře.
Dalším krokem byla aplikace metod matematické analýzy v teorii pravděpodobnosti. Tohoto úkolu se ujali významní matematici jako Laplace, Gauss, Poisson a Bernoulli. Byli to oni, kdo posunul tuto oblast matematiky na novou úroveň. Byl to James Bernoulli, kdo objevil zákon binomického rozdělení. Mimochodem, jak později zjistíme, na základě tohoto objevu bylo učiněno několik dalších, což umožnilo vytvořit zákon normálního rozdělení a mnoho dalších.
Nyní, než začneme popisovat binomické rozdělení, trochu si osvěžíme paměť pojmů teorie pravděpodobnosti, pravděpodobně již zapomenutých ze školní lavice.
Základy teorie pravděpodobnosti
Budeme uvažovat o takových systémech, v jejichž důsledku jsou možné pouze dva výsledky: „úspěch“ a „neúspěch“. To lze snadno pochopit na příkladu: hodíme si mincí a hádáme, že ocasy vypadnou. Pravděpodobnost každé z možných událostí (padnutí ocasu – „úspěch“, pád hlavy – „neúspěch“) se rovná 50 procentům, pokud je mince dokonale vyvážená a neexistují žádné další faktory, které mohou experiment ovlivnit.
Byla to ta nejjednodušší akce. Ale existují také komplexní systémy, ve kterém se provádějí sekvenční akce a pravděpodobnosti výsledků těchto akcí se budou lišit. Uvažujme například následující systém: v krabici, jejíž obsah nevidíme, je šest naprosto stejných míčků, tři páry modré, červené a bílé barvy. Musíme získat náhodně několik míčků. V souladu s tím tím, že nejprve vytáhneme jednu z bílých koulí, několikanásobně snížíme pravděpodobnost, že další dostaneme také bílou. K tomu dochází, protože se mění počet objektů v systému.
V další části se podíváme na složitější matematické pojmy, které nám přiblíží, co znamenají slova „normální rozdělení“, „binomické rozdělení“ a podobně.

Základy matematické statistiky
Ve statistice, která je jednou z oblastí aplikace teorie pravděpodobnosti, existuje mnoho příkladů, kdy data pro analýzu nejsou výslovně uvedena. Tedy ne v číslech, ale formou rozdělení podle vlastností, například podle pohlaví. Aby bylo možné na taková data aplikovat matematický aparát a ze získaných výsledků vyvodit nějaké závěry, je nutné převést výchozí data do číselného formátu. Aby to bylo možné realizovat, kladnému výsledku je zpravidla přiřazena hodnota 1 a zápornému 0. Získáme tak statistická data, která lze analyzovat pomocí matematických metod.
Dalším krokem k pochopení toho, co je binomické rozdělení náhodné veličiny, je určení rozptylu náhodné veličiny a matematického očekávání. O tom si povíme v další části.

Očekávaná hodnota
Porozumět tomu, co je to matematické očekávání, ve skutečnosti není obtížné. Uvažujme systém, ve kterém existuje mnoho různých událostí s vlastními různými pravděpodobnostmi. Matematické očekávání budeme nazývat hodnotou rovnající se součtu součinů hodnot těchto událostí (v matematické podobě, o které jsme hovořili v minulé části) a pravděpodobnosti jejich výskytu.
Matematické očekávání binomického rozdělení se vypočítá podle stejného schématu: vezmeme hodnotu náhodné veličiny, vynásobíme ji pravděpodobností pozitivního výsledku a poté shrneme získaná data pro všechny proměnné. Je velmi vhodné prezentovat tato data graficky - lépe se tak vnímá rozdíl mezi matematickými očekáváními různých hodnot.
V další části si řekneme něco o jiném konceptu – rozptylu náhodné veličiny. Také úzce souvisí s takovým konceptem, jako je binomické rozdělení pravděpodobnosti, a je jeho charakteristikou.

Binomické rozdělení rozptylu
Tato hodnota úzce souvisí s předchozí a také charakterizuje rozložení statistických dat. Představuje střední čtverec odchylek hodnot od jejich matematického očekávání. To znamená, že rozptyl náhodné veličiny je součtem čtverců rozdílů mezi hodnotou náhodné veličiny a jejím matematickým očekáváním, vynásobeným pravděpodobností této události.
Obecně je to vše, co potřebujeme vědět o rozptylu, abychom pochopili, co je binomické rozdělení pravděpodobnosti. Nyní přejděme k našemu hlavnímu tématu. Totiž, co se skrývá za tak zdánlivě dosti komplikovaným slovním spojením „zákon o binomickém rozdělení“.

Binomické rozdělení
Nejprve pochopíme, proč je toto rozdělení binomické. Pochází ze slova „binom“. Možná jste slyšeli o Newtonově binomu – vzorci, který lze použít k rozšíření součtu libovolných dvou čísel a a b na libovolnou nezápornou mocninu n.
Jak jste již pravděpodobně uhodli, Newtonův binomický vzorec a vzorec binomického rozdělení jsou téměř stejné vzorce. S jedinou výjimkou, že druhý má aplikovanou hodnotu pro konkrétní veličiny a první je pouze obecným matematickým nástrojem, jehož aplikace v praxi mohou být různé.
Distribuční vzorce
Funkci binomického rozdělení lze zapsat jako součet následujících členů:
(n!/(n-k)!k!)*p k *q n-k
Zde n je počet nezávislých náhodných experimentů, p je počet úspěšných výsledků, q je počet neúspěšných výsledků, k je číslo experimentu (může nabývat hodnot od 0 do n),! - označení faktoriálu, takové funkce čísla, jehož hodnota je rovna součinu všech čísel k němu jdoucích (např. pro číslo 4: 4!=1*2*3*4= 24).
Kromě toho lze binomickou distribuční funkci zapsat jako neúplnou beta funkci. To je však již složitější definice, která se používá pouze při řešení složitých statistických problémů.
Binomické rozdělení, jehož příklady jsme zkoumali výše, je jedním z nejjednodušších typů rozdělení v teorii pravděpodobnosti. Existuje také normální rozdělení, což je typ binomického rozdělení. Je nejpoužívanější a nejsnáze se počítá. Existuje také Bernoulliho distribuce, Poissonova distribuce, podmíněná distribuce. Všechny graficky charakterizují oblasti pravděpodobnosti určitého procesu za různých podmínek.
V další části se budeme zabývat aspekty souvisejícími s aplikací tohoto matematického aparátu v reálný život. Na první pohled se samozřejmě zdá, že jde o další matematickou věc, která jako obvykle nenachází uplatnění v reálném životě a kromě samotných matematiků ji obecně nikdo nepotřebuje. To však není tento případ. Ostatně všechny typy distribucí a jejich grafické znázornění byly vytvořeny výhradně pro praktické cíle a ne z rozmaru vědců.

aplikace
Zdaleka nejdůležitější aplikace distribuce se nachází ve statistice, protože vyžaduje komplexní analýza spousta dat. Jak ukazuje praxe, velmi mnoho datových polí má přibližně stejné rozložení hodnot: kritické oblasti velmi nízkých a velmi vysokých hodnot zpravidla obsahují méně prvků než průměrné hodnoty.
Analýza velkých datových polí je vyžadována nejen ve statistice. Nepostradatelný je například ve fyzikální chemii. V této vědě se používá k určení mnoha veličin, které jsou spojeny s náhodnými vibracemi a pohyby atomů a molekul.
V další části probereme, jak důležité je takové použití používat statistické pojmy, jako dvojčlen rozdělení náhodné veličiny v Každodenní život pro tebe a pro mě.

Proč to potřebuji?
Tuto otázku si klade mnoho lidí, když přijde řeč na matematiku. A mimochodem, matematika není nadarmo nazývána královnou věd. Je to základ fyziky, chemie, biologie, ekonomie a v každé z těchto věd se také používá nějaké rozdělení: jestli jde o diskrétní binomické rozdělení nebo normální, na tom nezáleží. A když se blíže podíváme na svět kolem nás, uvidíme, že matematika se používá všude: v každodenním životě, v práci a dokonce i mezilidské vztahy lze prezentovat ve formě statistických dat a analyzovat (toto mimochodem , dělají ti, kteří pracují ve speciálních organizacích zabývajících se sběrem informací).
Nyní si povíme něco málo o tom, co dělat, pokud potřebujete o tomto tématu vědět mnohem více, než co jsme nastínili v tomto článku.
Informace, které jsme uvedli v tomto článku, nejsou zdaleka úplné. Existuje mnoho nuancí ohledně toho, jakou formu může distribuce mít. Binomické rozdělení, jak jsme již zjistili, je jedním z hlavních typů, na kterých je celek matematické statistiky a teorie pravděpodobnosti.
Pokud vás zaujme, nebo v souvislosti s vaší prací potřebujete o tomto tématu vědět mnohem více, budete si muset prostudovat odbornou literaturu. Začněte univerzitním kurzem matematická analýza a dostat se tam do sekce teorie pravděpodobnosti. Užitečné budou také znalosti v oblasti řad, protože binomické rozdělení pravděpodobnosti není nic jiného než řada po sobě jdoucích členů.
Závěr
Před dokončením článku bychom vám rádi řekli ještě jednu zajímavost. Týká se přímo tématu našeho článku a celé matematiky obecně.
Mnoho lidí říká, že matematika je zbytečná věda a nic z toho, co se naučili ve škole, pro ně nebylo užitečné. Ale znalosti nejsou nikdy zbytečné, a pokud vám něco v životě není užitečné, znamená to, že si to prostě nepamatujete. Pokud máte znalosti, mohou vám pomoci, ale pokud je nemáte, nemůžete od nich čekat pomoc.
Prozkoumali jsme tedy koncept binomického rozdělení a všechny definice s ním spojené a mluvili jsme o tom, jak se používá v našich životech.
Samozřejmě, že při výpočtu kumulativní distribuční funkce je třeba použít zmíněný vztah mezi binomickým a beta rozdělením. Tato metoda je určitě lepší než přímá sumace, když n > 10.
V klasických učebnicích statistiky se pro získání hodnot binomického rozdělení často doporučuje používat vzorce založené na limitních teorémech (jako je Moivre-Laplaceův vzorec). Je třeba poznamenat, že z čistě výpočetního hlediska hodnota těchto teorémů se blíží nule, zvláště nyní, kdy je téměř na každém stole výkonný počítač. Hlavní nevýhodou výše uvedených aproximací je jejich zcela nedostatečná přesnost pro hodnoty n typické pro většinu aplikací. Nemenší nevýhodou je absence jasných doporučení ohledně použitelnosti té či oné aproximace (ve standardních textech jsou uváděny pouze asymptotické formulace, nejsou doprovázeny odhady přesnosti, a proto jsou málo použitelné). Řekl bych, že oba vzorce platí pouze pro n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Nemyslím zde problém hledání kvantilů: pro diskrétní rozdělení je to triviální a v těch problémech, kde taková rozdělení vznikají, to zpravidla není relevantní. Pokud jsou kvantily stále potřeba, doporučuji přeformulovat problém tak, aby se pracovalo s p-hodnotami (pozorované významy). Zde je příklad: při implementaci některých výčtových algoritmů je v každém kroku nutné zkontrolovat statistickou hypotézu o binomické náhodné veličině. Podle klasického přístupu je v každém kroku nutné vypočítat statistiku kritéria a porovnat jeho hodnotu s hranicí kritického souboru. Protože je však algoritmus enumerativní, je nutné hranici kritické množiny určovat pokaždé znovu (velikost vzorku se přeci jen mění krok od kroku), což neproduktivně zvyšuje časové náklady. Moderní přístup doporučuje vypočítat pozorovanou významnost a porovnat ji s pravděpodobností spolehlivosti, čímž se ušetří na hledání kvantilů.
Proto následující kódy nepočítají inverzní funkci, místo toho je uvedena funkce rev_binomialDF, která vypočítá pravděpodobnost p úspěchu v jediném pokusu za předpokladu počtu n pokusů, počtu m úspěchů v nich a hodnoty y pravděpodobnosti získání těchto m úspěchů. To využívá výše zmíněný vztah mezi binomickým a beta rozdělením.
Ve skutečnosti vám tato funkce umožňuje získat hranice intervalů spolehlivosti. Předpokládejme, že dosáhneme m úspěchů v n binomických pokusech. Jak víte, levý okraj je oboustranný interval spolehlivosti pro parametr p s hladinou spolehlivosti je 0, pokud m = 0, a for je řešením rovnice  . Podobně je pravá mez 1, pokud m = n, a for je řešením rovnice
. Podobně je pravá mez 1, pokud m = n, a for je řešením rovnice  . To znamená, že abychom našli levou hranici, musíme rovnici vyřešit
. To znamená, že abychom našli levou hranici, musíme rovnici vyřešit  , a hledat tu správnou - rovnici
, a hledat tu správnou - rovnici  . Jsou řešeny ve funkcích binom_leftCI a binom_rightCI , které vracejí horní a dolní mez oboustranného intervalu spolehlivosti.
. Jsou řešeny ve funkcích binom_leftCI a binom_rightCI , které vracejí horní a dolní mez oboustranného intervalu spolehlivosti.
Chci poznamenat, že pokud není potřeba absolutně neuvěřitelná přesnost, pak pro dostatečně velké n můžete použít následující aproximaci [B.L. van der Waerden, Matematická statistika. M: IL, 1960, Ch. 2, sec. 7]:  , kde g je kvantil normálního rozdělení. Hodnota této aproximace spočívá v tom, že existují velmi jednoduché aproximace, které umožňují vypočítat kvantily normálního rozdělení (viz text o výpočtu normálního rozdělení a odpovídající část tohoto odkazu). V mé praxi (hlavně pro n > 100) dávala tato aproximace asi 3-4 číslice, což je zpravidla docela dost.
, kde g je kvantil normálního rozdělení. Hodnota této aproximace spočívá v tom, že existují velmi jednoduché aproximace, které umožňují vypočítat kvantily normálního rozdělení (viz text o výpočtu normálního rozdělení a odpovídající část tohoto odkazu). V mé praxi (hlavně pro n > 100) dávala tato aproximace asi 3-4 číslice, což je zpravidla docela dost.
Výpočty s následujícími kódy vyžadují soubory betaDF.h , betaDF.cpp (viz část o beta distribuci) a také logGamma.h , logGamma.cpp (viz příloha A). Můžete se také podívat na příklad použití funkcí.
soubor binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(dvojité pokusy, dvojité úspěchy, dvojité p); /* * Nechť existují "zkoušky" nezávislých pozorování * s pravděpodobností "p" úspěchu v každém. * Vypočítejte pravděpodobnost B(úspěchy|pokusy,p), že počet * úspěchů je mezi 0 a "úspěchy" (včetně). */ double rev_binomialDF(dvojité pokusy, dvojité úspěchy, dvojité y); /* * Nechť je známa pravděpodobnost y alespoň m úspěchů * ve zkouškách Bernoulliho schématu. Funkce zjistí pravděpodobnost p * úspěchu v jediném pokusu. * * Ve výpočtech se používá následující vztah * * 1 - p = rev_Beta(pokusy-úspěchy| úspěchy+1, y). */ double binom_leftCI(dvojité pokusy, dvojité úspěchy, dvojitá úroveň); /* Nechť jsou "zkoušky" nezávislých pozorování * s pravděpodobností "p" úspěchu v každém * a počet úspěchů je "úspěchů". * Levá mez oboustranného intervalu spolehlivosti * se vypočítá s hladinou významnosti. */ double binom_rightCI(dvojité n, dvojité úspěchy, dvojitá úroveň); /* Nechť jsou "zkoušky" nezávislých pozorování * s pravděpodobností "p" úspěchu v každém * a počet úspěchů je "úspěchů". * Pravá mez oboustranného intervalu spolehlivosti * se vypočítá s hladinou významnosti. */ #endif /* Končí #ifndef __BINOMIAL_H__ */ |
soubor binomialDF.cpp
| /******************************************************* **** **********/ /* Binomické rozdělení */ /****************************** **** *********************************/ #zahrnout |
Ahoj! Už víme, co je rozdělení pravděpodobnosti. Může být diskrétní nebo spojitý a my jsme se naučili, že se nazývá rozdělení hustoty pravděpodobnosti. Nyní se podívejme na několik běžnějších distribucí. Předpokládejme, že mám minci a správnou minci a hodím ji 5krát. Definuji také náhodnou veličinu X, označím ji velkým písmenem X, bude se rovnat počtu „orlů“ za 5 hodů. Možná mám 5 mincí, hodím je všechny najednou a spočítám, kolik hlav mám. Nebo bych mohl mít jednu minci, mohl bych ji hodit 5x a spočítat, kolikrát jsem dostal hlavy. To je vlastně jedno. Ale řekněme, že mám jednu minci a hodím ji 5x. Pak nebudeme mít žádnou nejistotu. Takže zde je definice mé náhodné proměnné. Jak víme, náhodná veličina se od běžné proměnné mírně liší, je to spíše funkce. Přiřadí experimentu nějakou hodnotu. A tato náhodná veličina je docela jednoduchá. Jen spočítáme, kolikrát „orel“ vypadl po 5 hodech - to je naše náhodná proměnná X. Pojďme se zamyslet nad tím, jaké jsou pravděpodobnosti různých hodnot v našem případě? Jaká je tedy pravděpodobnost, že X (velké X) je 0? Tito. Jaká je pravděpodobnost, že po 5 hodech už to nikdy nepřijde v úvahu? No, to je vlastně totéž, jako pravděpodobnost, že dostaneme nějaké „ocasy“ (to je pravda, malý přehled teorie pravděpodobnosti). Měli byste dostat nějaké "ocasy". Jaká je pravděpodobnost každého z těchto „ocasů“? Toto je 1/2. Tito. mělo by to být 1/2 krát 1/2, 1/2, 1/2 a znovu 1/2. Tito. (1/2)⁵. 1⁵=1, děleno 2⁵, tzn. ve 32. Celkem logické. Takže... trochu zopakuji, čím jsme si prošli na teorii pravděpodobnosti. To je důležité, abychom pochopili, kde se nyní pohybujeme a jak to vlastně je diskrétní distribuce pravděpodobnosti. Jaká je tedy pravděpodobnost, že dostaneme hlavy právě jednou? No, hlavy se mohly objevit při prvním hodu. Tito. mohlo by to být takto: „orel“, „ocasy“, „ocasy“, „ocasy“, „ocasy“. Nebo by se při druhém hodu mohly objevit hlavy. Tito. mohla by existovat taková kombinace: „ocasy“, „hlavy“, „ocasy“, „ocasy“, „ocasy“ a tak dále. Jeden „orel“ mohl vypadnout po kterémkoli z 5 hodů. Jaká je pravděpodobnost každé z těchto situací? Pravděpodobnost získání hlav je 1/2. Potom se pravděpodobnost získání "ocasů", rovna 1/2, vynásobí 1/2, 1/2, 1/2. Tito. pravděpodobnost každé z těchto situací je 1/32. Stejně jako pravděpodobnost situace, kdy X=0. Ve skutečnosti bude pravděpodobnost jakéhokoli zvláštního pořadí hlav a ocasů 1/32. Takže pravděpodobnost toho je 1/32. A pravděpodobnost toho je 1/32. A k takovým situacím dochází proto, že „orel“ může spadnout na kterýkoli z 5 hodů. Pravděpodobnost, že vypadne právě jeden „orel“, se tedy rovná 5 * 1/32, tzn. 5/32. Celkem logické. Nyní začíná to zajímavé. Jaká je pravděpodobnost… (každý z příkladů napíšu jinou barvou)… jaká je pravděpodobnost, že moje náhodná veličina je 2? Tito. Hodím mincí 5x a jaká je pravděpodobnost, že dopadne přesně na hlavu 2x? Tohle je zajímavější, že? Jaké kombinace jsou možné? Mohou to být hlavy, hlavy, ocasy, ocasy, ocasy. Mohly to být také hlavy, ocasy, hlavy, ocasy, ocasy. A pokud si myslíte, že tito dva „orli“ mohou stát na různých místech kombinace, můžete se trochu zmást. Už nemůžete přemýšlet o umístěních tak, jak jsme to udělali zde výše. I když... můžete, jen riskujete, že budete zmatení. Musíte pochopit jednu věc. Pro každou z těchto kombinací je pravděpodobnost 1/32. ½*½*½*½*½. Tito. pravděpodobnost každé z těchto kombinací je 1/32. A měli bychom se zamyslet nad tím, kolik existuje takových kombinací, které splňují naši podmínku (2 "orli")? Tito. ve skutečnosti si musíte představit, že existuje 5 hodů mincí a musíte si vybrat 2 z nich, ve kterých „orel“ vypadne. Předstírejme, že našich 5 hodů je v kruhu, také si představme, že máme jen dvě židle. A my říkáme: „Dobře, kdo z vás bude sedět na těchto židlích pro Orly? Tito. kdo z vás bude "orel"? A nezajímá nás pořadí, v jakém se posadí. Uvádím takový příklad a doufám, že vám to bude jasnější. A když mluvím o Newtonově binomii, možná se budete chtít podívat na nějaké tutoriály teorie pravděpodobnosti na toto téma. Protože tam se tomu všemu budu věnovat podrobněji. Ale pokud budete uvažovat tímto způsobem, pochopíte, co je binomický koeficient. Protože pokud uvažujete takto: OK, mám 5 hodů, který hod přistane první hlavy? No, tady je 5 možností, které flip přistanou první hlavy. A kolik příležitostí pro druhého "orla"? No, první hod, který jsme už použili, nám vzal jednu šanci na hlavy. Tito. jedna pozice hlavy v kombu je již obsazena jedním z hodů. Nyní zbývají 4 hody, což znamená, že druhý „orel“ může padnout na jeden ze 4 hodů. A viděl jsi to, přímo tady. Rozhodl jsem se mít hlavy na 1. hodu a předpokládal jsem, že na 1 ze 4 zbývajících hodů by měly přijít také hlavy. Zde jsou tedy pouze 4 možnosti. Říkám jen, že pro první hlavu máte 5 různých pozic, na které může přistát. A na druhou zbývají už jen 4 pozice. Přemýšlejte o tom. Když takto počítáme, bere se v úvahu pořadí. Ale pro nás je teď jedno, v jakém pořadí vypadnou „hlavy“ a „ocasy“. Neříkáme, že je to "eagle 1" nebo že je to "eagle 2". V obou případech jde jen o „orla“. Mohli bychom předpokládat, že toto je hlava 1 a toto je hlava 2. Nebo to může být naopak: může to být druhý „orel“ a toto je „první“. A říkám to proto, že je důležité pochopit, kde používat umístění a kde používat kombinace. Posloupnost nás nezajímá. Takže vlastně existují jen 2 způsoby vzniku naší akce. Takže to vydělme 2. A jak později uvidíte, jsou to 2! způsoby vzniku naší akce. Kdyby byly 3 hlavy, byly by 3! a já vám ukážu proč. Takže to by bylo... 5*4=20 děleno 2 je 10. Existuje tedy 10 různých kombinací z 32, kde určitě budete mít 2 hlavy. Takže 10*(1/32) se rovná 10/32, co to znamená? 5/16. Budu psát přes binomický koeficient. Toto je hodnota tady nahoře. Pokud se nad tím zamyslíte, je to stejné jako 5! děleno ... Co znamená toto 5 * 4? 5! je 5*4*3*2*1. Tito. pokud zde potřebuji pouze 5 * 4, pak mohu rozdělit 5! za 3! To se rovná 5*4*3*2*1 děleno 3*2*1. A zbývá jen 5 * 4. Je to tedy stejné jako tento čitatel. A pak, protože sekvence nás nezajímá, tady potřebujeme 2. Vlastně 2!. Vynásobte 1/32. To by byla pravděpodobnost, že trefíme přesně 2 hlavy. Jaká je pravděpodobnost, že dostaneme hlavy přesně 3x? Tito. pravděpodobnost, že x=3. Takže podle stejné logiky může dojít k prvnímu výskytu hlav v 1 z 5 otočení. Druhý výskyt hlav se může objevit u 1 ze 4 zbývajících hodů. A třetí výskyt hlav se může objevit na 1 ze 3 zbývajících hodů. Kolik různých způsobů existuje pro uspořádání 3 hodů? Obecně, kolik způsobů existuje, jak uspořádat 3 předměty na jejich místa? Jsou 3! A můžete na to přijít, nebo možná budete chtít znovu navštívit tutoriály, kde jsem to vysvětlil podrobněji. Ale když si vezmete třeba písmena A, B a C, tak je 6 způsobů, jak je můžete uspořádat. Můžete si to představit jako nadpisy. Zde může být ACB, CAB. Může to být BAC, BCA a... Jaká je poslední možnost, kterou jsem nejmenoval? CBA. Existuje 6 způsobů, jak uspořádat 3 různé položky. Dělíme 6, protože těch 6 nechceme znovu počítat různé způsoby protože s nimi zacházíme jako s rovnocennými. Zde nás nezajímá, jaký počet hodů bude mít za následek hlavy. 5*4*3… Toto lze přepsat jako 5!/2!. A vydělte to ještě 3!. Tohle je on. 3! rovná se 3*2*1. Trojky se zmenšují. Z toho se stane 2. Toto se stane 1. Ještě jednou 5*2, tzn. je 10. Každá situace má pravděpodobnost 1/32, takže toto je opět 5/16. A je to zajímavé. Pravděpodobnost, že získáte 3 hlavy, je stejná jako pravděpodobnost, že získáte 2 hlavy. A důvod pro to... No, existuje mnoho důvodů, proč se to stalo. Ale když se nad tím zamyslíte, pravděpodobnost získání 3 hlav je stejná jako pravděpodobnost získání 2 ocasů. A pravděpodobnost získání 3 ocasů by měla být stejná jako pravděpodobnost získání 2 hlav. A je dobře, že hodnoty takto fungují. Pokuta. Jaká je pravděpodobnost, že X=4? Můžeme použít stejný vzorec, jaký jsme použili dříve. Mohlo by to být 5*4*3*2. Takže zde píšeme 5 * 4 * 3 * 2 ... Kolik různých způsobů existuje pro uspořádání 4 objektů? Jsou 4!. 4! - to je ve skutečnosti tato část, přímo tady. To je 4*3*2*1. Takže toto se zruší a zůstane 5. Pak má každá kombinace pravděpodobnost 1/32. Tito. to se rovná 5/32. Znovu si všimněte, že pravděpodobnost, že dostanete hlavy 4krát, se rovná pravděpodobnosti, že se hlavy objeví 1krát. A to dává smysl, protože. 4 hlavy jsou stejné jako 1 ocas. Řeknete si: no, a při jakém házení vypadnou tyhle „ocásky“? Ano, existuje na to 5 různých kombinací. A každý z nich má pravděpodobnost 1/32. A nakonec, jaká je pravděpodobnost, že X=5? Tito. vrhne se 5x za sebou. Mělo by to být takto: „orel“, „orel“, „orel“, „orel“, „orel“. Každá z hlav má pravděpodobnost 1/2. Vynásobíte je a dostanete 1/32. Můžete jít jinou cestou. Pokud existuje 32 způsobů, jak můžete v těchto experimentech získat hlavy a ocasy, pak je to jen jeden z nich. Zde bylo takových způsobů 5 z 32. Zde - 10 z 32. Přesto jsme provedli výpočty a nyní jsme připraveni nakreslit rozdělení pravděpodobnosti. Ale můj čas vypršel. Dovolte mi pokračovat v další lekci. A pokud budete mít náladu, možná si před sledováním nakreslete další lekce? Brzy se uvidíme!



